Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Desenvolvedor de pipeline de bioinformática
Você tem dados de expressão gênica rotulados e precisa de
um classificador de IA para prever os subtipos de câncer ou resultados de pacientes?
Vou montar uma pipeline completa de classificação de IA
adaptada ao seu conjunto de dados genômicos.
O QUE VOCÊ RECEBE:
- Pré-processamento e normalização dos dados
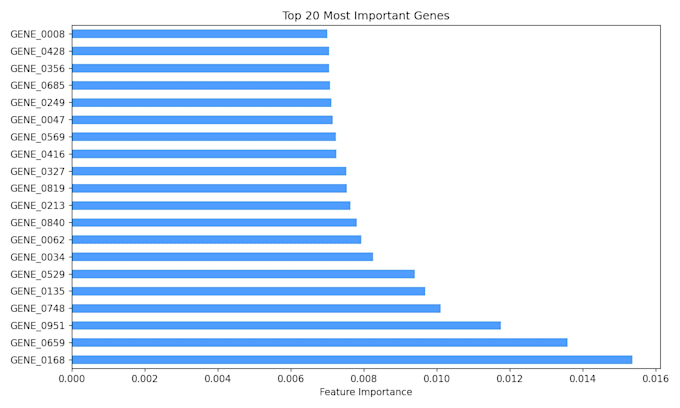
- Seleção de características para identificar os genes mais informativos
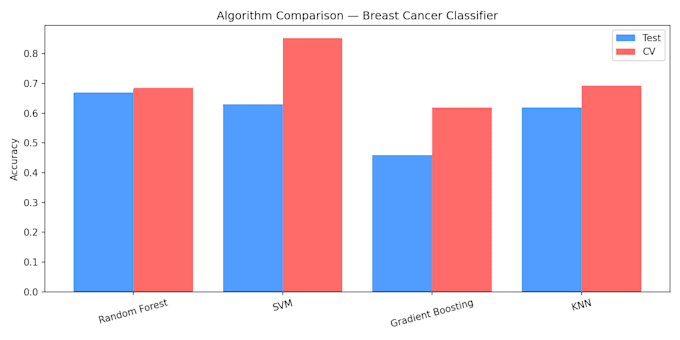
- Comparação de múltiplos algoritmos (Random Forest, SVM,
Gradient Boosting, KNN)
- Avaliação de acurácia com validação cruzada
- Matriz de confusão e relatório de classificação
- Visualização da importância das características
- Modelo salvo pronto para produção
MINHA EXPERIÊNCIA:
Criei um classificador de subtipos de câncer de mama usando dados de expressão gênica, atingindo 85,2% de acurácia na validação cruzada com SVM. Classifiquei 4 subtipos: LuminalA, LuminalB, HER2, TriploNegativo.
Pipeline completo disponível no GitHub.
O QUE PRECISO DE VOCÊ:
- Matriz de expressão gênica (amostras x genes)
- Rótulos de subtipo ou resultado para cada amostra
- Número de classes a serem previstas
- Genes ou vias importantes conhecidas
FERRAMENTAS: Python, scikit-learn, Pandas, numpy,
matplotlib, seaborn, joblib, Linux, Git



Especialidade:
Classificação
•
agrupamento
•
Análise preditiva
Linguagem de programação:
Python
•
R
Frameworks:
Scikit-learn
•
Panda
APIs:
Outros
Ferramentas:
caderno Jupyter
•
RStudio