Ver categorias
Explorar
Fiverr Pro
Português
$
USD
vamos fazer seu projeto acontecer
Bem-vindo ;
Sou Engenheiro de Big Data com 5 anos de experiência,
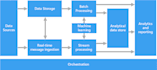
Posso te ajudar a construir seu projeto de big data, incluindo injeção de dados (usando Apache Kafka), armazenamento de dados (em Hadoop ou Amazon S3 ou seu Data Lake remoto), processamento de dados em batch ou stream (em tempo real) com pySpark ou pyFlink, análise de dados (usando machine learning e MLlib para big data), e também análise e visualização em dashboard
Bem, meus serviços incluem:
Reembolso de 100% se o trabalho não for feito conforme o requisito.
NOTA:
Pedidos personalizados também são aceitos. Por favor, envie uma mensagem antes de fazer o pedido.
Obrigado por estar aqui. Me envie uma mensagem agora para começar.
Atenciosamente,


Especialidade:
Automações
•
Big data
•
etl
•
Transformação
•
SQL
•
NoSQL
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Cliente recorrente

Estados Unidos
Good and very knowledgeable
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
anushabandari
Cliente recorrente
Estados Unidos
Good and very knowledgeable


