Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Cientista de dados, Engenheiro de soluções IA, Especialista em IA agentic
Dados bagunçados estão te atrasando? A maioria dos projetos de Ciência de Dados falha por causa da má qualidade dos dados. Estou aqui para ajudar. Ofereço serviços especializados de Limpeza de Dados, Análise Exploratória de Dados (EDA) e Engenharia de Features para garantir que seus dados sejam precisos, reveladores e "prontos para o modelo".
O que eu ofereço:
1. Limpeza Profissional de Dados
2. Análise Exploratória de Dados (EDA) aprofundada
3. Engenharia de Features avançada
Ferramentas & Tecnologias:
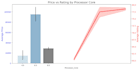
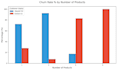
Uso Python com bibliotecas padrão da indústria: Pandas, NumPy, Seaborn, Matplotlib e Scikit-learn.
Entregáveis: Você receberá um conjunto de dados limpo (CSV/Excel) e um Jupyter Notebook totalmente documentado (.ipynb) com todo o código e visualizações.


Tradução automática
O que preciso fornecer para começar?
Por favor, envie seu conjunto de dados em formato CSV, Excel ou SQL junto com uma breve descrição dos seus objetivos. Se você tiver perguntas específicas que quer que a Análise Exploratória de Dados (EDA) responda, sinta-se à vontade para listá-las!
Quais ferramentas você usa para limpeza de dados e EDA?
Eu principalmente uso Python com bibliotecas poderosas como Pandas e NumPy para manipulação de dados, e Matplotlib ou Seaborn para visualizações de dados de alta qualidade.
Você consegue lidar com conjuntos de dados muito bagunçados e com valores ausentes?
Sim! Essa é minha especialidade. Uso técnicas avançadas de imputação (média, mediana, moda ou preenchimento preditivo) e detecção de outliers para garantir que seus dados estejam consistentes e prontos para análise.
O que é "Feature Engineering" e por que eu preciso disso?
Feature Engineering é o processo de criar novas variáveis a partir dos seus dados brutos para ajudar os modelos de Machine Learning a terem um desempenho melhor. Por exemplo, transformar uma coluna "Data" em "Dia da Semana" ou "É Feriado". Isso agrega um valor significativo aos seus modelos preditivos.
O que significa "100 itens limpos" nos seus pacotes?
Na categoria de Limpeza de Dados, a Fiverr define um mínimo de 100 itens. Eu considero esses "itens" como pontos de dados ou linhas. Meu pacote Básico foi criado para fornecer limpeza de alta qualidade e EDA para conjuntos de dados padrão. Se seu arquivo tiver várias milhares de linhas, não se preocupe—posso lidar com isso dentro do pacote listado.
Vou receber o código-fonte?
Com certeza. Eu entregarei um Jupyter Notebook bem documentado (.ipynb) ou um script Python para que você possa ver exatamente como os dados foram transformados e recriados no futuro.
Meus dados estão seguros com você?
Sim, levo a privacidade dos dados muito a sério. Seus dados serão usados apenas para o escopo do projeto e serão excluídos do meu sistema assim que o pedido for concluído e aceito.


