Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro DevOps
Pare de adivinhar sobre a saúde do seu servidor.
Com mais de 2 anos de experiência em DevOps, eu construo pilhas de monitoramento e observabilidade de nível empresarial usando Prometheus, Grafana, Loki e Datadog para detectar problemas antes que afetem seus usuários.
Ajudo startups e empresas a obterem visibilidade total em ambientes de nuvem, Kubernetes e locais.
O que eu ofereço:
Por que me escolher?
Entre em contato antes de fazer seu pedido para discutir suas necessidades.
Tradução automática
Você pode migrar meus alertas de nuvem existentes para uma solução mais econômica?
Sim, posso migrar seus alertas de infraestrutura existentes de qualquer provedor de nuvem para uma configuração de Grafana gerenciada por você. Essa migração pode economizar centenas de dólares em custos de monitoramento, mantendo alta visibilidade da sua infraestrutura.
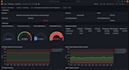
O que você monitora no servidor?
Monitoração de RAM, CPU, armazenamento, tráfego de rede e verificações de status. Também configuro 5 alertas para essas métricas e notificações por email caso algum limite seja atingido.
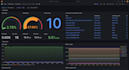
Quais problemas do Kubernetes você pode monitorar?
Ofereço monitoramento extensivo de Kubernetes, incluindo falhas de nó e pod, uso elevado de CPU e memória, utilização de espaço em disco, erros CrashLoopBackOff e ImagePullBackOff, pods pendentes, expiração de certificados, evacuações de pod, reinícios de pod, adição automática de nós, saúde e sincronização do ArgoCD e muitos outros.
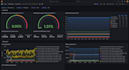
Que tipo de monitoramento você oferece para aplicações Docker?
Eu ofereço monitoramento completo para aplicações Docker, incluindo monitoramento de endpoints e rastreamento de portas específicas. Assim, seus ambientes Docker ficam totalmente monitorados quanto ao desempenho e disponibilidade.
Você configura alertas para monitoramento de infraestrutura?
Sim, configuro alertas para todas as métricas monitoradas, incluindo desempenho do servidor, aplicações Docker e clusters Kubernetes. Você receberá notificações por email sempre que um limite for atingido ou se surgir algum problema crítico, garantindo que você esteja sempre informado.


