Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro de Dados Líder
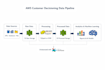
Sou um Engenheiro de Dados Sênior com mais de 6 anos de experiência projetando pipelines de dados escaláveis e plataformas de dados na nuvem. Especializo-me em criar fluxos de trabalho de ETL confiáveis, transformando dados brutos em conjuntos de dados estruturados e possibilitando sistemas de dados prontos para análise.
Posso ajudar você com:
-Desenvolvimento de pipelines de ETL usando Python, SQL e PySpark
-Ingestão de dados de APIs, arquivos e bancos de dados
-Transformação e otimização de dados
-Pipelines de dados na nuvem usando AWS (S3, EMR, Redshift, Glue, Kinesis, Athena)
-Arquitetura Lakehouse (camadas Bronze, Silver, Gold)
-Integração de data warehouse e ajuste de performance
Foco em construir pipelines de dados eficientes, escaláveis e prontos para produção que suportem análises, relatórios e workflows de machine learning.
Se precisar de ajuda para projetar ou melhorar seu pipeline de dados ou plataforma de dados, sinta-se à vontade para entrar em contato antes de fazer seu pedido.

Warehouse Platform:
Snowflake
•
redshift
•
PostgreSQL / Greenplum
Tipo de projeto:
New Build
