Ver categorias
Explorar
Fiverr Pro
Português
$
USD

Level 2


Tradução automática
Seus clientes não vão permitir que você envie os dados deles para o ChatGPT. Eu entendo. Vou criar um aplicativo de desktop para Windows que roda um verdadeiro LLM Phi-3, Llama 3, Mistral, Qwen ou Gemma totalmente na máquina do usuário
Sem nuvem. Sem chaves de API. Sem vazamento de dados. Sem contas recorrentes na OpenAI. Sem dores de cabeça com GDPR. Sem preocupações com HIPAA.
Sou um desenvolvedor sênior Windows (mais de 13 anos) atualmente trabalhando em ferramentas de depuração de hardware em uma empresa global de semicondutores. Entendo ONNX Runtime, DirectML, aceleração GPU/NPU e como embalar um modelo de 24 GB dentro de um instalador MSIX ou Inno Setup sem quebrar.
Perfeito para:
Pilha tecnológica: C# / WPF/ WinUI, ONNX Runtime GenAI, llama.cpp, Microsoft.ML.OnnxRuntime, DirectML, Semantic Kernel (modo local), LiteDB para armazenamento de vetores, empacotamento MSIX / Inno Setup
Requisitos de hardware que vou ajudar a planejar: recomendarei especificações mínimas para seus usuários finais com base no tamanho do modelo
Windows Desktop Developer C Sharp, C plus plus , Python , WPF, XAML, AI
Level 2
Idiomas
Tradução automática
Tradução automática
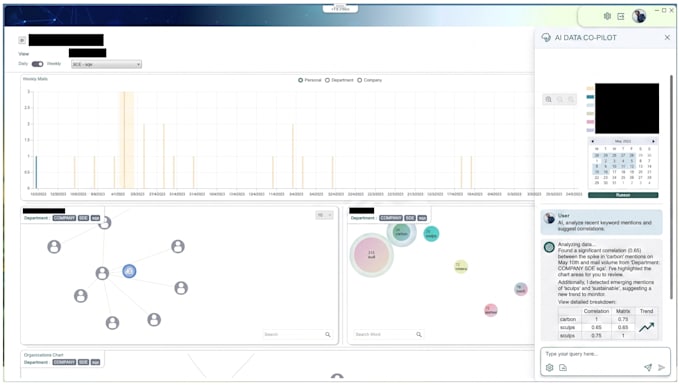
Quão bons são os modelos locais comparados ao GPT-4?
Honestamente, não são melhores em tudo — mas surpreendentemente próximos em muitas tarefas. Phi-3-mini e Llama 3 8B lidam muito bem com Q&A, sumarização, extração e elaboração de textos. Para tarefas que exigem amplo conhecimento do mundo ou raciocínio complexo, os modelos na nuvem ainda lideram.
Qual o tamanho do instalador final?
Entre 2 GB e 8 GB, dependendo do modelo. Uso instaladores que baixam o modelo na primeira execução, se você preferir uma download inicial menor.
Isso vai funcionar em um laptop de 5 anos?
Sim, com um modelo menor (Phi-3-mini, 3.8B de parâmetros) no CPU — mais lento, talvez 3–6 tokens por segundo. Para respostas em tempo real, recomenda-se RAM de 16 GB e um CPU moderno.
Pode usar a NPU em PCs mais novos com Copilot+?
Sim. ONNX Runtime com DirectML pode direcionar a NPU em Qualcomm Snapdragon X e NPUs mais novos da Intel/AMD para inferência muito mais rápida com menor consumo de energia.
E se eu quiser atualizar o modelo depois?
Os pacotes Standard e Premium incluem um mecanismo de troca de modelo, para que você (ou seus usuários) possam inserir um modelo mais novo ou diferente sem precisar de um novo instalador.
Você faz fine-tuning?
Fine-tuning é um serviço separado. Para a maioria dos casos, RAG (recuperar de seus próprios documentos) oferece o mesmo resultado prático sem o custo e a complexidade do fine-tuning. Vou aconselhar honestamente qual você precisa.
Você pode assinar um HIPAA BAA?
Não assino BAAs como freelancer solo, mas seu aplicativo pode ser HIPAA-compliant por design — exatamente o que eu construo. Vou explicar a diferença na nossa primeira conversa.
E quanto à licença comercial dos modelos?
Uso apenas modelos com licenças permissivas (Phi-3 MIT, Llama 3 com licença comercial da Meta, Mistral Apache 2.0, Qwen). Avisarei sobre implicações de licenciamento antes de finalizarmos qual modelo usar.