Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Ciência de Dados e Inteligência Artificial
Procurando algo mais do que um script básico de NLP?
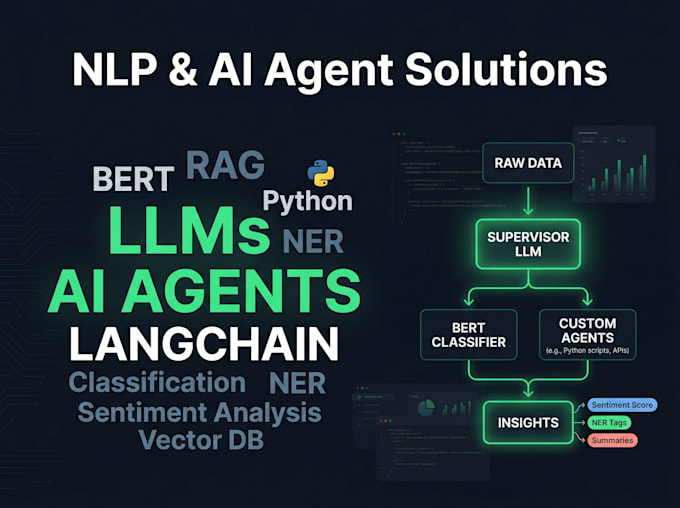
Eu crio sistemas inteligentes de texto de ponta a ponta, desde pipelines clássicos de NLP até modelos BERT ajustados e agentes de IA prontos para produção, alimentados por LangGraph e LangChain. Seja um classificador de sentimento, um chatbot específico de domínio ou um sistema completo de múltiplos agentes LLM, entrego soluções limpas, documentadas e prontas para implantação.
O que eu ofereço:
1. NLP & Análise de Texto
Pré-processamento de texto: tokenização, remoção de stopwords, lematização (spaCy / NLTK)
Classificação de texto & Análise de sentimento (Naive Bayes, SVM, Regressão Logística)
Reconhecimento de entidades nomeadas (NER), extração de palavras-chave e frases-chave
TF-IDF, análise de N-gramas, frequência de palavras, redes de coocorrência
Modelagem de tópicos LDA, NMF, BERTopic
Resumão de texto & similaridade semântica
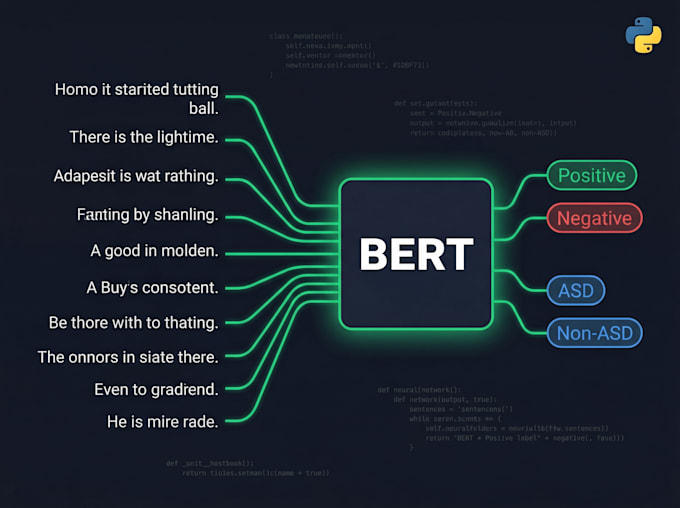
2. Ajuste fino de BERT & Transformer
Ajuste fino de BERT, RoBERTa, DistilBERT, AraBERT no seu conjunto de dados personalizado
Classificação de sequências, classificação de tokens, resposta a perguntas
Curvas de treinamento, relatório de avaliação (precisão, F1, matriz de confusão)
Salvar & exportar pesos do modelo (formato HuggingFace, .pth, .zip)
3. Agentes de IA & Soluções LLM
Orquestração de múltiplos agentes usando LangGraph, domínio específico



Linguagem de programação:
Python
•
MATLAB
•
SQL
•
Colab
Frameworks:
Scikit-learn
•
PyTorch
•
Panda
APIs:
Outros
Ferramentas:
caderno Jupyter
•
opencv
•
fluxo tensor
•
Excel
•
Colab
Tradução automática
Q1: Com que tipo de dados de texto você trabalha?
Qualquer domínio — texto médico/clínico, avaliações de clientes, posts em redes sociais, comentários no YouTube, documentos legais, artigos acadêmicos, relatórios financeiros, respostas de pesquisas. Se você tem texto, posso criar algo com ele.
Q2: Preciso de um conjunto de dados rotulado para classificação?
Para tarefas supervisionadas (classificação, sentimento) — sim, dados rotulados são necessários. Para tarefas não supervisionadas (modelagem de tópicos, clustering, extração de palavras-chave) — texto bruto serve. Posso também aconselhar sobre estratégia de rotulagem se estiver começando do zero.
Q3: Você pode construir um sistema RAG para meus documentos ou base de conhecimento?
Sim — isso faz parte do pacote Premium. Vou configurar uma loja de vetores (FAISS ou Chroma), conectá-la aos seus documentos e criar um pipeline de recuperação do LangChain para que seu LLM responda perguntas estritamente a partir dos seus dados.
Q4: Com quais LLMs você trabalha?
OpenAI GPT-3.5 / GPT-4, Groq (LLaMA 3, Mixtral), Google Gemini, Mistral. Posso trabalhar com qualquer um que você prefira ou já tenha acesso via API. Também posso usar modelos open-source locais via Ollama, se quiser zero custos de API.
Q5: Vou poder rodar e modificar o código eu mesmo?
Com certeza. Todos os entregáveis são notebooks Jupyter/Colab limpos, bem comentados. Escrevo código para humanos, não só para máquinas. Você entenderá cada passo, e fico feliz em explicar qualquer coisa após a entrega.
Q6: Você pode implantar o modelo ou agente como uma API ou aplicativo web?
Implantação básica (endpoint FastAPI ou app Streamlit) pode ser adicionada como extra. Para implantação completa na nuvem (AWS, GCP, Hugging Face Spaces), entre em contato antes de pedir para um orçamento personalizado.