Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Transformando suas ideias em soluções, sites e crescimento digital!
SEUS DADOS ESTÃO PRESOS NO PASSADO? CHEGOU A HORA DE IR A SÉRIO
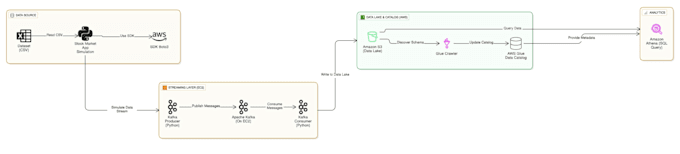
Sou um Engenheiro de Dados Cloud especializado, com experiência em criar arquiteturas de dados de alto desempenho. Recentemente, projetei um Pipeline de Streaming de Mercado de Ações em Tempo Real capaz de lidar com alta volatilidade de dados usando Apache Kafka e AWS, e vou criar essa mesma qualidade de nível empresarial para o seu negócio.
Meu Stack Técnico:
O que vou construir para você:
Por que me escolher? Diferente de desenvolvedores genéricos, eu entendo Dados Financeiros. Meu código é modular, bem documentado e pronto para produção.
️
POR FAVOR, ME ENVIE UMA MENSAGEM ANTES DE PEDIR para discutir suas necessidades específicas de arquitetura!

Tradução automática
Preciso fornecer minhas próprias credenciais de conta AWS?
Sim. Para que eu possa implantar o pipeline, preciso de um usuário IAM com permissões adequadas (acesso a S3, EC2, Redshift). Posso orientar você sobre como criar isso de forma segura, sem compartilhar sua senha de root.
Executar esse pipeline vai ficar caro na minha conta AWS?
Eu projeto pensando em eficiência de custos. Uso recursos elegíveis para o "Free Tier" (como instâncias t2.micro para Kafka) sempre que possível e configuro políticas de ciclo de vida do S3 para arquivar dados antigos, mantendo seus custos de operação baixos.
Você oferece suporte se o pipeline quebrar após a entrega?
Sim. Os pacotes Padrão e Premium incluem um período de suporte pós-entrega (5-7 dias) para corrigir bugs relacionados ao meu código. Também forneço um guia de como reiniciar serviços se eles pararem.
Qual API você usa para buscar dados do mercado de ações?
Normalmente uso yfinance ou Alpha Vantage para simulação em tempo real. No entanto, o pipeline é modular. Posso trocar o script "Producer" para ingerir dados de qualquer API financeira que você preferir (por exemplo, Polygon.io ou IEX Cloud).
Como você lida com alta volatilidade ou picos de dados no mercado?
A arquitetura usa Apache Kafka como buffer. Se o mercado enviar um pico massivo de dados, o Kafka os armazena com segurança até que os consumidores (Spark/Python) possam processar, garantindo que nenhum dado seja perdido durante tráfego intenso.
Por que você usa Zookeeper nessa arquitetura?
Zookeeper gerencia os brokers do Kafka. Ele acompanha o status dos nós do Kafka e mantém o controle de quais tópicos e partições estão ativos. É essencial para a tolerância a falhas do cluster de streaming.
Quão "em tempo real" é o processamento de dados?
A latência é extremamente baixa. O Kafka Producer busca os preços das ações instantaneamente, e o Consumer os processa quase em tempo real (geralmente em milissegundos a alguns segundos), tornando-o adequado para dashboards ao vivo.
Em que formato você armazena os dados no S3?
Normalmente, armazeno os dados em formato Parquet ou CSV. Parquet é altamente recomendado para dados financeiros porque é comprimido e colunar, o que torna consultas via AWS Athena ou Redshift muito mais rápidas e baratas.
Esse pipeline lida com dados duplicados?
Sim. Implemento lógica no script do Consumer (usando Spark ou Python Pandas) para eliminar duplicatas com base em timestamps e IDs de ações antes de carregar os dados finais limpos no seu banco de dados.
Posso conectar esse pipeline a um dashboard como PowerBI ou Tableau?
Com certeza. Como os dados finais chegam ao AWS Redshift ou S3, você pode conectar diretamente PowerBI, Tableau ou AWS QuickSight para visualizar as tendências ao vivo das ações.