Ver categorias
Explorar
Fiverr Pro
Português
$
USD
O que fazemos
Serviços principais
Processo
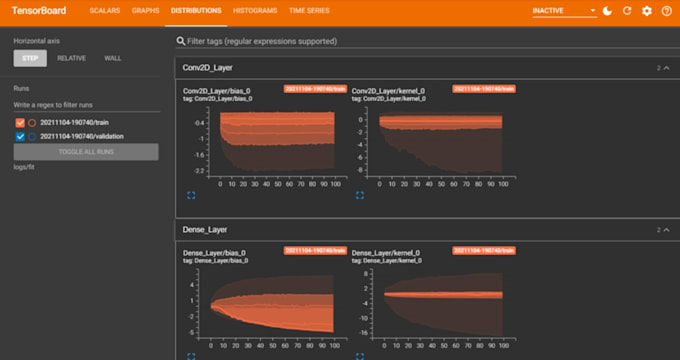
Pilha
PyTorch, TensorFlow, HF, scikit-learn, Optuna, MLflow, ONNX/TensorRT, Docker/FastAPI
Propriedade
Você possui o código e os pesos. Custos de GPU na nuvem cobrados pelas taxas do provedor. NDA/white-label disponível.
Para começar

Linguagem de programação:
Python
•
MATLAB
•
Colab
•
MLflow
•
Julia
Frameworks:
Scikit-learn
•
DeepPy
•
keras
•
PyTorch
•
Panda
•
fluxo tensor
Tradução automática
Você vai assinar um NDA?
Sim. Estou confortável com NDA e/ou uma cláusula de confidencialidade mútua. Trabalho com marca branca também é tranquilo.
Como vocês protegem meus dados?
Acesso com privilégios mínimos, repositórios privados, armazenamento criptografado (quando na nuvem) e sem compartilhamento com terceiros. Eu excluo conjuntos de dados e artefatos mediante solicitação ou 14 dias após a entrega.
Quem possui o modelo e o código?
Você. Transferência completa dos pesos treinados, código fonte e documentação. Nota: modelos base/bibliotecas de código aberto mantêm suas licenças originais.
Quais são os prazos de entrega típicos?
Básico: 7 dias, Padrão: 14 dias, Premium: 28 dias. Opções de entrega ultra rápida estão disponíveis em Extras.
O que pode impactar os prazos?
Tamanho/qualidade dos dados, rotulagem, número de tentativas de HPO, requisitos de conformidade e complexidade de implantação (nuvem, escalabilidade, segurança).
Você consegue implantar o modelo para uso em produção?
Sim. O pacote Premium inclui implantação na nuvem; o Padrão fornece uma estrutura de API. Posso fornecer uma API REST Dockerizada com verificações de saúde e documentação.
Quais stacks você suporta?
PyTorch/TensorFlow, Hugging Face, ONNX/TensorRT, FastAPI + Docker. Eu integro com AWS/GCP/Azure, Vercel/DO ou sua infraestrutura local.
Eu consigo exportar para mobile/edge?
Sim, exportação do modelo para ONNX; TFLite/Core ML mediante solicitação, sujeito à compatibilidade do modelo.
O que está incluído na documentação?
Notas de configuração, comandos de execução, especificações do endpoint, relatório de avaliação e um cartão do modelo cobrindo métricas, dados e limitações.
Vocês fornecem manutenção?
Sim. Manutenção mensal opcional (correções de bugs, pequenas atualizações) está disponível como Extra ou plano personalizado.