Ver categorias
Explorar
Fiverr Pro
Português
$
USD
FREELANCER HABILIDOSO COMPROMETIDO COM CONTEÚDOS DE QUALIDADE
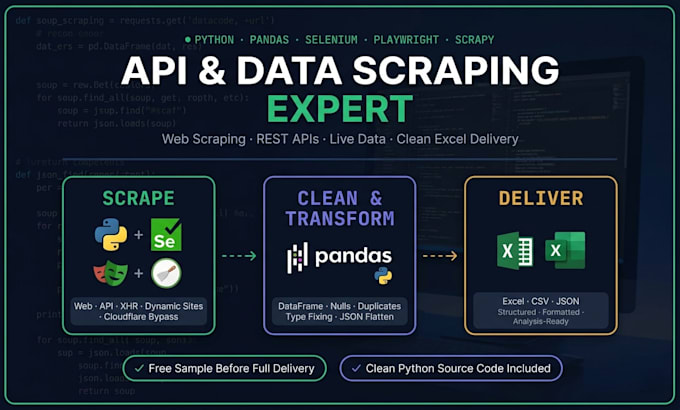
Vou fazer scraping de sites dinâmicos e endpoints de API.
Precisa de dados de qualquer site, API oculta ou feed ao vivo, estruturados, limpos e prontos para usar? Você está no lugar certo.
Eu faço tanto web scraping dinâmico quanto extração de endpoints de API de páginas renderizadas com JavaScript até APIs XHR/Fetch reversamente engenheiradas, entregando tudo através de um pipeline completo de limpeza e formatação com Pandas.
O QUE VOCÊ RECEBE:
Scraping de sites dinâmicos
Descoberta e engenharia reversa de endpoints de API (XHR/Fetch)
Scraping de tokens de API REST, cabeçalhos de autenticação, gerenciamento de sessões
Bypass de Cloudflare, Turnstile e anti-bot
Dados em tempo real de placares esportivos, criptomoedas, preços, listagens
JSON aninhado convertido em planilhas estruturadas
Saída em Excel / CSV / JSON
️ TECNOLOGIAS:
Python · Pandas · Selenium · Playwright · Scrapy · Requests · BeautifulSoup · openpyxl
POR QUE ESCOLHER MIM :
Tanto scraping de sites quanto extração de API, tudo em um vendedor, cobertura total
Amostra grátis antes da entrega completa
Script Python reutilizável incluído com cada pedido
Arquivos limpos, tipados e formatados, sem dumps brutos
Especialista em Turnstile e Cloudflare
Envie uma mensagem primeiro para verificar a viabilidade, sem compromisso.


 (1)_kv3che.jpg)
 (1)_h3ydiz.jpg)
Tecnologia:
Python
•
Excel
•
selenium
•
Beautiful Soup
•
Pandas
Tipo de informação:
Sites
Técnica:
Automatizado
Tradução automática
Q1: Qual a diferença entre web scraping e API scraping?
Web scraping extrai dados diretamente do HTML de um site — útil para páginas sem API pública. API scraping intercepta chamadas de backend ocultas feitas pelo site (requisições XHR/Fetch) para obter dados mais limpos, rápidos e confiáveis. Faço ambos — o que for melhor para seu site específico.
Q2: Você consegue fazer raspagem de sites renderizados em JavaScript ou sites dinâmicos?
Sim. Uso Selenium e Playwright para renderizar completamente páginas em JavaScript, lidar com scroll infinito, lazy loading e conteúdo AJAX antes de extrair os dados — assim nada fica de fora.
Q3: Você consegue passar pelo Cloudflare ou Turnstile?
Sim. Tenho experiência prática em capturar tokens do Cloudflare Turnstile, incluindo desafios ativados por scroll e baseados em user-agent — um dos sistemas de proteção contra bots mais complexos atualmente em uso. Envie uma mensagem com seu site alvo para uma verificação de viabilidade gratuita.
Q4: O que realmente significa 'limpeza e formatação de dados'?
Antes da entrega, cada conjunto de dados passa por um pipeline completo de Pandas: valores nulos tratados, duplicatas removidas, tipos de dados corrigidos, nomes de colunas padronizados, JSON aninhado achatado e formatado em Excel com cabeçalhos e larguras de coluna adequados. Você recebe um arquivo finalizado, profissional — não um dump bruto.
Q5: Você vai fornecer o script em Python?
Sim — cada pedido inclui código fonte limpo, comentado e reutilizável em Python, para que você possa rodar o scraper novamente a qualquer momento sem precisar contratar de novo.
Q6: Quais formatos de saída você entrega?
Excel (.xlsx), CSV e JSON por padrão. Entrega via Google Sheets disponível mediante solicitação. Basta mencionar sua preferência antes de pedir.
Q7: Web scraping é legal?
Trabalho apenas com dados acessíveis ao público e não faço scraping de sites que proíbam explicitamente em seus Termos de Serviço. Nunca extraio dados privados de usuários ou bypass paywalls. Envie uma mensagem com a URL do seu alvo antes de pedir, para que eu possa confirmar a viabilidade e conformidade.
P8: Como começar?
Envie uma mensagem antes de fazer seu pedido. Compartilhe a URL do seu alvo, os campos de dados que precisa e o volume aproximado. Eu confirmarei a viabilidade, o prazo e quaisquer desafios técnicos — totalmente grátis, sem compromisso.