Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Projetos de sistemas e IA, C Python SQL, pontual e otimizado
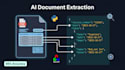
Você está afogado em PDFs, faturas, formulários ou imagens escaneadas que precisam de extração de dados? Eu construo sistemas de IA prontos para produção que fazem isso automaticamente.
Sou engenheiro de IA e visão computacional com experiência prática na criação de pipelines de deep learning de ponta a ponta, desde dados brutos até uma solução funcional e implantável que você pode realmente usar.
O QUE EU CONSTRUO
Processamento Inteligente de Documentos (IDP)
Extraia dados estruturados de faturas, recibos, contratos, formulários médicos, documentos fiscais e qualquer formato personalizado de PDF ou imagem.
Pipelines de OCR Personalizados
Além do OCR básico, eu crio sistemas de IA que entendem layout, tabelas, caixas de seleção e escrita manual usando TesseractOCR, PaddleOCR e deep learning.
Visão Computacional e Detecção de Objetos
Modelos personalizados YOLO (v8/v11), classificação de imagens, segmentação e rastreamento de objetos treinados com seu próprio conjunto de dados.
Desenvolvimento de Modelos IA/ML
CNN, RNN, LSTM para classificação, regressão, extração de texto NLP e previsão de séries temporais.
Implantação de Modelos e API
API REST via FastAPI ou Flask, containerização com Docker, implantação na nuvem (AWS, GCP), integração com seu frontend.
FERRAMENTAS & STACK
Python, PyTorch, TensorFlow, OpenCV, YOLO, PaddleOCR, Tesseract

Linguagem de programação:
Python
•
SQL
•
Colab
•
JAVA
•
MLflow
Frameworks:
Scikit-learn
•
Google ML Kit
•
keras
•
PyTorch
•
Panda
Tradução automática
Preciso fornecer dados de treinamento?
Depende do projeto. Para tipos comuns de documentos como faturas ou recibos, posso usar modelos pré-treinados e adaptá-los ao seu formato. Para documentos altamente personalizados ou layouts proprietários, um conjunto de dados de 50 a 200 exemplos é ideal. Se você não tiver um, posso orientar sobre como coletar e
Em qual formato os dados extraídos serão entregues?
Por padrão, entrego saída estruturada em JSON ou CSV. Se precisar em banco de dados, arquivo Excel ou integrado ao seu sistema via API, isso pode ser organizado — é só mencionar ao me contactar.
Qual será a precisão da extração?
A precisão depende da qualidade e complexidade do documento. Para PDFs digitais limpos, geralmente atinge 95–99%. Para documentos escaneados ou manuscritos, 85–95% é realista. Sempre faço testes nos seus documentos reais antes da entrega e incluo um relatório de desempenho.
É possível trabalhar com documentos em outros idiomas além do inglês?
Sim. PaddleOCR suporta mais de 80 idiomas e tenho experiência com pipelines multilíngues. Por favor, mencione seu idioma ao me contactar.
Eu vou ter propriedade do código?
Sim, 100%. Todo o código fonte, pesos do modelo e documentação são seus. Não retenho direitos sobre o que eu criar para você.


