Ver categorias
Explorar
Fiverr Pro
Português
$
USD





Tradução automática
Cansado de processar documentos manualmente? Deixe a IA fazer isso em segundos.
Vou criar uma pipeline personalizada de OCR e Inteligência de Documentos que extrai, processa e analisa texto de PDFs, arquivos digitalizados, folhas manuscritas e imagens, entregando um resultado limpo, estruturado e pronto para produção.
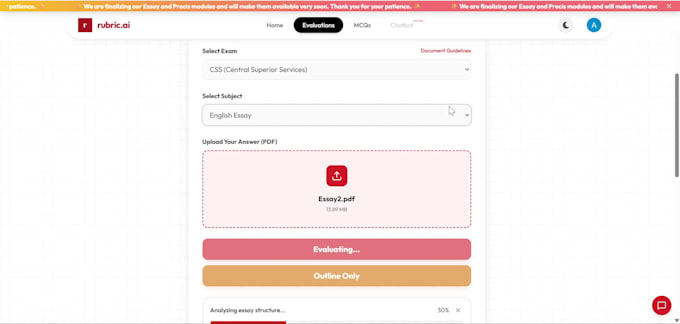
Já construí e implementei sistemas reais de OCR como o Rubric Ai, incluindo uma plataforma de avaliação de exames com IA e sistemas automatizados de processamento de faturas com usuários reais, não apenas projetos de teste.
O que eu construo: pipeline de OCR para PDFs, imagens e documentos digitalizados Pré-processamento para entradas ruidosas, manuscritas e de baixa qualidade Análise com IA e extração inteligente de texto Anotação automatizada e motor de avaliação Saída estruturada em JSON/CSV pronta para integração Backend FastAPI e integração com banco de dados
Perfeito para: Processamento de documentos jurídicos, médicos e financeiros Automação de exames, avaliações e notas Extração de dados de faturas, recibos e contratos
Por que me escolher: Sistemas de OCR reais e implantados, não apenas tutoriais Lida com manuscritos, línguas mistas e digitalizações ruins Código limpo, fonte completa incluída, entrega no prazo
Me envie uma mensagem e vamos definir o escopo do seu projeto antes de você fazer o pedido.
Ai and Computer vision Solutions
Idiomas
Tradução automática
Tradução automática
Você pode criar um sistema personalizado de avaliação ou classificação de documentos?
Com certeza. Já criei motores de avaliação com LLM baseados em rubricas que pontuam e anotam documentos seção por seção. Seja para avaliação de exames, revisão de contratos ou validação de formulários, posso desenvolver uma pipeline de avaliação inteligente adaptada aos seus critérios.
Que tipos de documentos seu pipeline de OCR consegue processar?
Meu pipeline de OCR lida com PDFs, imagens digitalizadas, documentos fotografados e folhas manuscritas. Funciona com digitalizações de baixa qualidade, conteúdo em línguas mistas e entradas ruidosas, incluindo pré-processamento para garantir extração de texto limpa e precisa toda vez.
Você consegue integrar o sistema de OCR com minha aplicação ou banco de dados existentes?
Sim. Eu construo backends REST com FastAPI que se conectam diretamente à sua aplicação. Suporto MongoDB e PostgreSQL para armazenamento estruturado de dados e posso fornecer saída limpa em JSON ou CSV compatível com qualquer sistema downstream.
O que é inteligência de documentos e como ela difere do OCR básico?
O OCR básico apenas extrai texto. A inteligência de documentos vai além — usando LLMs para analisar, classificar, anotar e avaliar o conteúdo extraído com base em critérios definidos. É a diferença entre ler um documento e realmente entendê-lo.
Vocês fornecem código-fonte e documentação?
Sim, toda entrega inclui o código fonte completo, comentários detalhados e documentação de configuração para que sua equipe possa manter e expandir o sistema de forma independente, sem depender de mim.
Quanto tempo leva para construir uma pipeline completa de inteligência de documentos?
Uma pipeline básica de extração de OCR leva cerca de 3 dias. Um sistema completo de inteligência de documentos com análise de IA, motor de anotação, API e integração com banco de dados normalmente leva de 7 a 10 dias, dependendo da complexidade. Me envie uma mensagem primeiro para obter um cronograma preciso para seu projeto.