Serviços profissionais de Engenharia de Dados | Pipelines ETL | AWS | Databricks
Quer criar pipelines de dados escaláveis e confiáveis para seu negócio?
Sou um Engenheiro de Dados com mais de 6 anos de experiência projetando e otimizando pipelines ETL usando tecnologias modernas de nuvem e big data.
O que posso fazer por você:
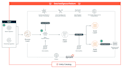
- Construir pipelines ETL de ponta a ponta (Extrair, Transformar, Carregar)
- Desenvolver jobs PySpark / Spark para processamento de dados em grande escala
- Projetar lakes de dados na AWS S3
- Criar fluxos de trabalho usando Apache Airflow
- Implementar soluções Databricks para análise e ML
- Otimizar pipelines para performance e eficiência de custos
- Integrar dados de APIs, bancos de dados e arquivos (CSV, JSON, Parquet)
️ Stack Tecnológico:
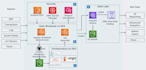
- AWS: S3, Glue, IAM, CloudWatch
- Databricks
- Apache Spark / PySpark
- Apache Airflow
- Python / SQL
Por que me escolher?
- Construí pipelines que lidam com conjuntos de dados de múltiplos terabytes
- Foco forte em otimização de performance
- Código limpo, fácil de manter e pronto para produção
- Comunicação rápida e entrega confiável
Casos de uso exemplos:
- Pipelines de data warehouse
- Arquitetura de data lake
- Workflows em batch e agendados
- Limpeza e transformação de dados
- Pipelines de ingestão de API para S3