Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Farei ciência de dados ou análise de dados
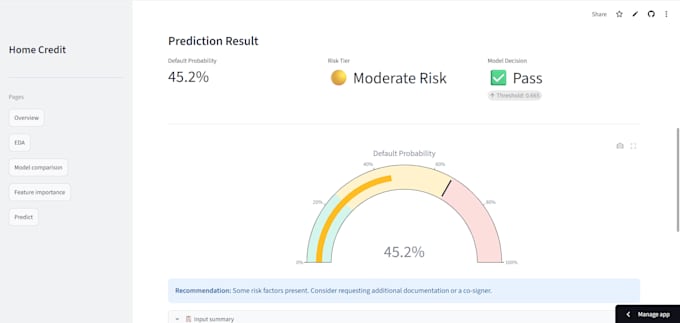
Demo ao vivo: credit-risk-prediction-better.streamlit.app
GitHub: github.com/Niqar/Credit-risk-prediction
Você tem dados brutos, mas não sabe como transformá-los em um modelo de ML funcional? Eu vou montar uma pipeline completa de machine learning, pronta para produção, do dado bagunçado até um modelo que realmente funciona.
O que vou entregar:
Limpeza de dados e engenharia de features (lidar com valores ausentes, codificação, escalonamento)
Treinamento de modelo com LightGBM, XGBoost, Random Forest ou Regressão Logística
Hiperparâmetros otimizados com Optuna para o melhor desempenho
Relatório completo de avaliação (AUC, F1-score, Precisão, Recall, Matriz de Confusão)
Pipeline do scikit-learn limpo, reproduzível e pronto para deploy
Jupyter Notebook + código Python documentado
Repositório no GitHub (a pedido)
Por que trabalhar comigo:
Eu não apenas treino um modelo e entrego. Documentei cada passo para que você entenda o que foi feito e por quê, e garanto que a pipeline seja limpa o suficiente para reutilizar ou estender.
Confira meu portfólio: credit-risk-prediction-better.streamlit.app
Sinta-se à vontade para me enviar uma mensagem antes de fazer o pedido. Vou revisar seu dataset e confirmar se posso ajudar.



Linguagem de programação:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
•
PyTorch
Ferramentas:
caderno Jupyter
•
opencv
•
fluxo tensor
•
Excel
•
Colab
Tradução automática
Com que tipo de dados você trabalha?
Eu trabalho com dados estruturados/tabelados — CSV, Excel ou exportações SQL. Isso cobre problemas de classificação (fraude, churn, risco de crédito) e problemas de regressão (previsão de preço, previsão de vendas). Para dados de imagem ou texto, por favor, envie uma mensagem primeiro para que eu possa avaliar o escopo.
E se meu conjunto de dados estiver bagunçado ou com valores ausentes?
Isso é totalmente normal — lidar com dados bagunçados faz parte do que eu faço. Vou limpar, tratar valores ausentes, codificar features categóricos e escalar os numéricos como parte de cada pacote.
Quais modelos de aprendizado de máquina você usa?
Principalmente LightGBM, XGBoost, Random Forest e Regressão Logística — dependendo dos seus dados e objetivo. Nos pacotes Standard e Premium, treino e comparo vários modelos para que você tenha o melhor desempenho.
Vou poder reutilizar ou modificar o código eu mesmo?
Sim. Todo o código é limpo, comentado e estruturado como uma pipeline do scikit-learn — assim fica fácil treinar com novos dados ou ajustar os parâmetros. Também vou explicar as partes principais para você não ficar na dúvida.