Ver categorias
Explorar
Fiverr Pro
Português
$
USD



Tradução automática
Sobre este serviço
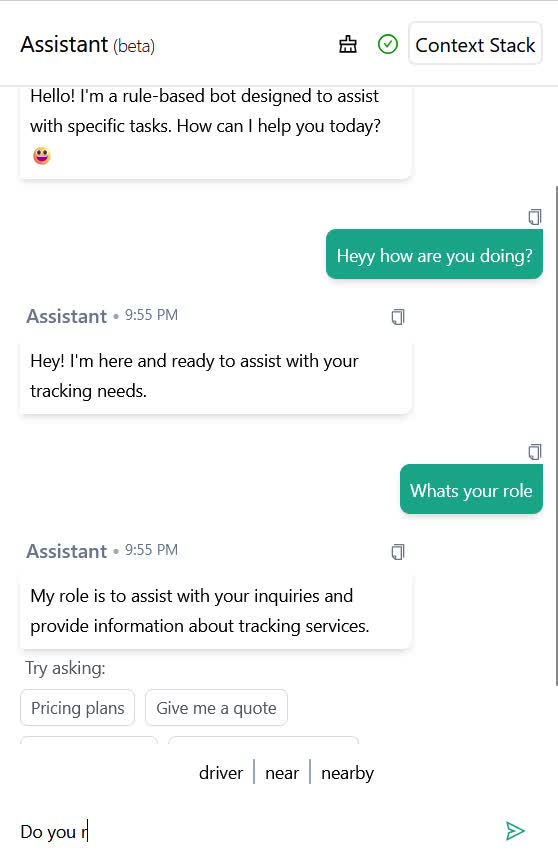
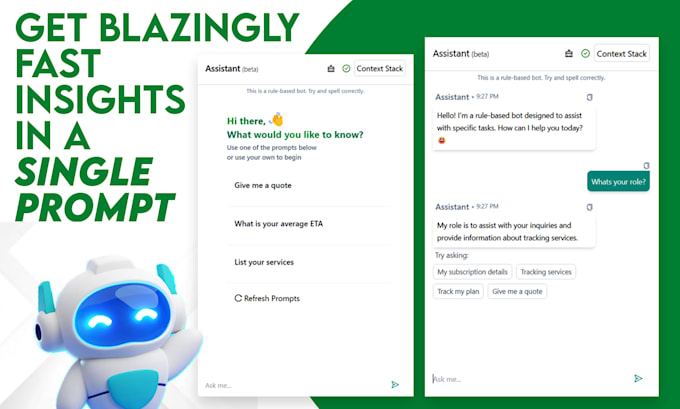
Tenho experiência em desenvolver serviços de chatbot com IA, habilitados para RAG e baseados em regras, em jornadas de conversa predefinidas por você!
Tipos de fluxos de trabalho que podem ser integrados:
Comece sua jornada para se destacar como um produto, serviço ou negócio excepcional, integrando fluxos de trabalho com IA e proporcionando uma ótima experiência ao usuário!
Idiomas
Tradução automática
Tradução automática
O serviço de chatbot pode ser totalmente baseado em regras, ou seja, sem fluxo de trabalho com IA?
Sim! Meu plano premium permite que você forneça uma jornada de conversa predefinida que pode funcionar exclusivamente com a intenção e palavras-chave do usuário.
O custo pela integração via API de LLM está incluso no plano?
Modelos como Grok, Claude e ChatGPT da OpenAI, que oferecem APIs para integração de LLM, terão custos adicionais com base no plano de preços escolhido pelo cliente junto ao provedor de LLM.
Como isso é econômico?
Isso depende do nível de precisão de resposta desejado pelo cliente. Uma opção econômica pode rodar um LLM pequeno sem a necessidade de um servidor GPU!