Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Crie aplicativos web inteligentes com IA e soluções de PLN para dados
Título: Organização Automática de Documentos & Análise NLP
Oi! Se você está sobrecarregado com uma pilha enorme de documentos PDF, posso te ajudar a organizá-los usando NLP com IA.
Eu não apenas agrupo arquivos por palavras-chave básicas. Uso embeddings semânticos avançados para entender o significado real do seu texto, garantindo que seus documentos sejam categorizados de forma lógica e precisa.
O que eu ofereço:
Foco na precisão e código limpo. Me envie uma mensagem hoje para discutir seu projeto!




Linguagem de programação:
Python
Frameworks:
Scikit-learn
•
Panda
Ferramentas:
caderno Jupyter
•
Colab
Tradução automática
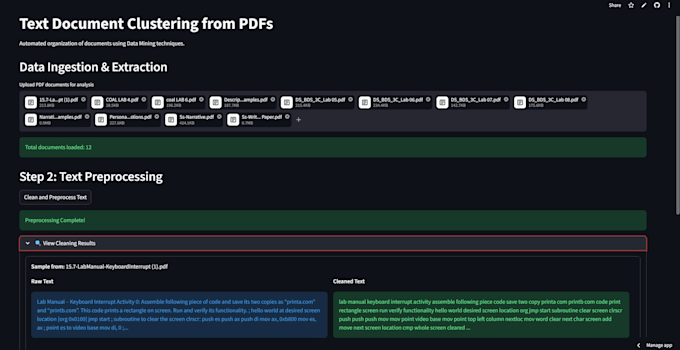
Que tipo de documentos PDF você consegue processar?
Posso processar quase qualquer PDF baseado em texto, incluindo artigos de pesquisa, relatórios de negócios e artigos.
Você também consegue processar arquivos do Microsoft Word (.docx)?
Sim, com certeza! Embora a versão padrão da minha ferramenta seja otimizada para PDFs, posso facilmente modificar o pipeline de ingestão de dados para lidar com arquivos .docx e .doc.
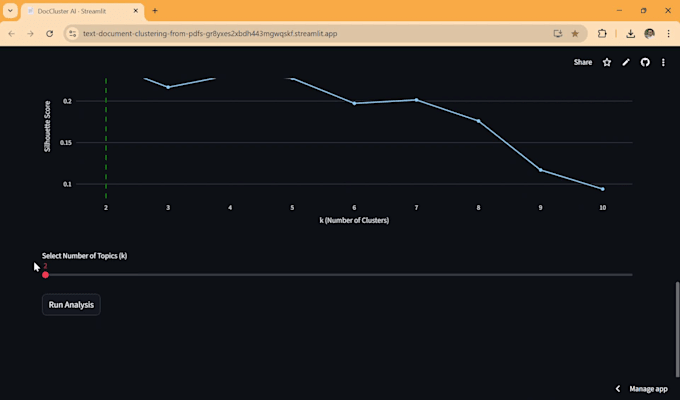
Como você garante que os clusters sejam precisos?
Uso uma análise de "Silhouette Score" para determinar matematicamente o número mais lógico de grupos para seus dados. Isso garante que os clusters não sejam apenas aleatórios, mas baseados na densidade semântica real.
Preciso fornecer os "Tópicos" antes?
Não! Isso é "Aprendizado Não Supervisionado", ou seja, a IA identifica os padrões e agrupa os documentos sozinha.
Meus dados estão seguros?
Com certeza. Processamos seus dados localmente em meu ambiente de desenvolvimento seguro. Assim que o projeto for entregue e aceito, excluo seus documentos do meu sistema, a menos que você peça o contrário.
Posso rodar o dashboard do Streamlit no meu computador?
Sim. Se você escolher o pacote Premium, forneço um arquivo requirements.txt e uma configuração .devcontainer, facilitando rodar o app localmente no VS Code ou implantá-lo na nuvem.