Ver categorias
Explorar
Fiverr Pro
Português
$
USD
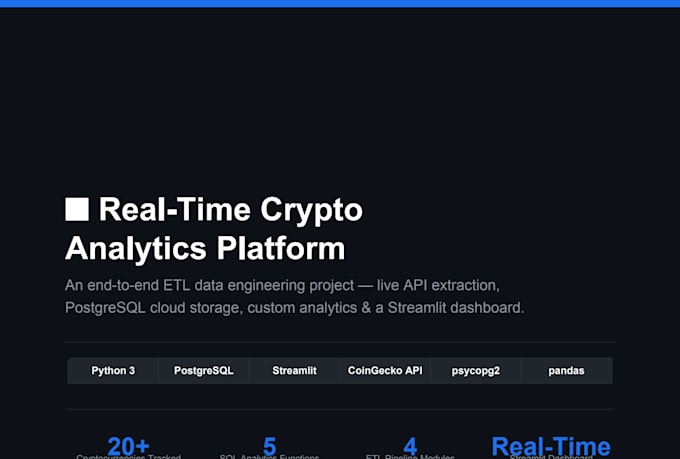
Transformo Dados em Inteligência Usando Machine Learning e Deep Learning
Procurando por modelos de ML precisos, prontos para produção, que resolvam problemas reais? Você está no lugar certo.
Eu crio soluções completas de aprendizado de máquina e deep learning em Python, desde dados brutos e desorganizados até modelos preditivos totalmente funcionais e pipelines de dados.
O QUE VOCÊ RECEBE
PROJETOS REAIS ENTREGUES
Código limpo. Explicações claras. Resultados reais.
Me envie uma mensagem antes de fazer seu pedido, vamos discutir seu projeto!

Linguagem de programação:
Python
•
SQL
Frameworks:
Scikit-learn
•
keras
APIs:
Outros
Ferramentas:
caderno Jupyter
•
fluxo tensor
•
Excel
•
MLflow
•
Colab
Tradução automática
Que tipo de problemas de ML você pode resolver?
Posso resolver uma ampla variedade de problemas de ML supervisionado e não supervisionado, incluindo regressão (previsão de preços, previsão de vendas), classificação (detecção de spam, previsão de churn, etc), clustering e detecção de anomalias. Se você não tiver certeza se seu problema se encaixa, envie uma mensagem e eu te aviso.
Preciso fornecer meu próprio dataset?
Sim, idealmente você deve fornecer seu dataset. No entanto, se não tiver um, posso buscar um dataset público relevante (do Kaggle, UCI ou APIs abertas) para seu problema. Quanto melhor seus dados, mais precisa será sua modelagem — então compartilhar dados reais sempre traz os melhores resultados.
Em que formato serão entregues os arquivos?
Você receberá um Jupyter Notebook (.ipynb) limpo com o código fonte completo, explicações bem comentadas e visualizações. Nos pacotes Standard e Premium, também entrego um relatório em PDF ou documentação do modelo. Todos os arquivos são enviados em um arquivo ZIP, tudo organizado e pronto para uso.
Você pode garantir uma precisão específica do modelo?
Nenhum profissional de ML pode garantir uma precisão fixa, pois ela depende muito da qualidade, tamanho dos dados e da complexidade do problema. O que eu garanto é que aplicarei as melhores técnicas de pré-processamento, engenharia de features e otimização de modelos para maximizar o desempenho. Sempre mostrarei a métrica de avaliação.
Quais bibliotecas e ferramentas de Python você usa?
Principalmente uso scikit-learn, Pandas, NumPy, Matplotlib e Seaborn para ML e análise de dados. Para pipelines e bancos de dados, uso PostgreSQL, psycopg2 e MySQL. Para dashboards, uso Streamlit. Para tarefas de deep learning, uso TensorFlow/Keras. Todas as bibliotecas são padrão da indústria e amplamente suportadas.
Vou entender o código mesmo se não for técnico?
Com certeza. Cada notebook é escrito com comentários claros, explicando passo a passo o que cada bloco de código faz e por quê. Nos pacotes Standard e Premium, também incluo um resumo escrito dos resultados e descobertas em inglês simples, para que você entenda os insights, não só o código.
Você consegue implantar o modelo para que eu possa usar ao vivo?
Sim, implantação na nuvem e integração via API estão incluídas no pacote Premium. Posso implantar seu modelo como um app web Streamlit ou um endpoint de API REST, pronto para produção. Se precisar de implantação em uma plataforma específica (AWS, Render), envie uma mensagem antes de fazer seu pedido para alinharmos a configuração.
E se eu precisar de algo personalizado que não esteja nos seus pacotes?
Sem problema algum. Envie uma mensagem com seus requisitos e eu te envio uma oferta personalizada, feita sob medida para suas necessidades. Seja um dataset exclusivo, um algoritmo específico, um pipeline maior ou um projeto combinado de ML + dashboard. Estou à disposição para discutir e orçar.
Meus dados são mantidos confidenciais?
100% sim. Seus dados são usados exclusivamente para completar seu projeto e nunca são compartilhados, publicados ou reutilizados de qualquer forma. Se precisar de um Acordo de Confidencialidade (NDA) antes de compartilhar dados sensíveis, posso assinar. Sua privacidade e segurança de dados são levadas a sério em todos os projetos.
Como funcionam as revisões?
Básico inclui 1 revisão, Padrão inclui 2, e Premium inclui 3. Uma revisão cobre ajustes no escopo existente, como ajustar parâmetros do modelo, alterar visualizações ou corrigir bugs. Não inclui adicionar funcionalidades ou algoritmos totalmente novos além do escopo acordado.