Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro de Dados na nuvem, BigQuery, Snowflake, dbt, Python, ETL
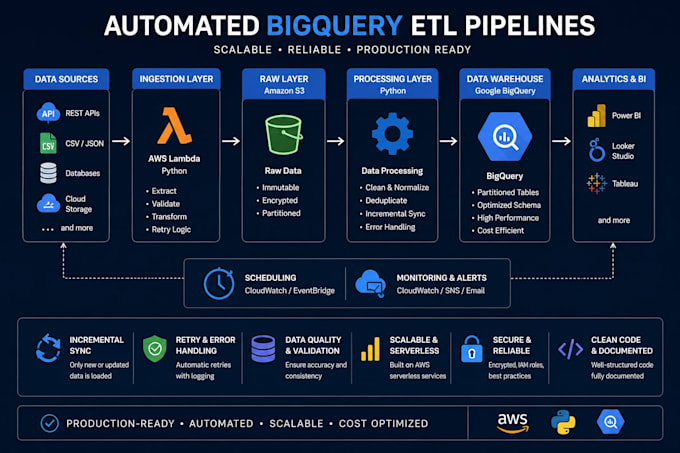
Construa um pipeline ETL escalável e pronto para produção, vindo de APIs, CSV, JSON, bancos de dados ou armazenamento na nuvem, direto para o Google BigQuery.
Sou especialista em pipelines de dados automatizados baseados em Python para análises, relatórios, Power BI, Looker Studio, Tableau e plataformas de inteligência de negócios.
Serviços incluem:
Ingestão de API no BigQuery
Carregamento incremental de dados
Backfill histórico
Normalização de JSON / CSV
Pipelines agendados automatizados
AWS Lambda / arquitetura serverless
Retry & tratamento de erros
Logging & monitoramento
Deduplicação de dados
Tabelas particionadas no BigQuery
Arquitetura Raw Staging Curated
Estruturas de warehouse prontas para dbt
Tecnologias:
- Python
- BigQuery
- AWS Lambda
- S3 / GCS
- Airflow / Prefect
- dbt
- APIs REST
Casos de uso típicos:
- Análises de e-commerce
- Relatórios financeiros
- Dashboards de marketing
- Integrações de CRM
- Sistemas de relatórios automatizados
Foco em arquiteturas escaláveis, fáceis de manter e prontas para produção, ao invés de scripts simples.
Por favor, entre em contato antes de fazer o pedido para projetos personalizados ou de grande escala.
Revisões não incluem mudanças de escopo ou integrações adicionais.





Tradução automática
Você suporta conjuntos de dados grandes?
Sim. Eu projeto pipelines escaláveis para milhões de registros e cargas de trabalho de produção.
Você consegue fazer deploy na AWS?
Sim. Posso implementar arquiteturas serverless usando Lambda, S3, Step Functions e CloudWatch.
Você consegue otimizar os custos do BigQuery?
Sim. Uso particionamento, clustering, processamento incremental e padrões de consulta otimizados.
Qual arquitetura você prefere para seu pipeline de dados?
Posso construir o pipeline usando arquitetura nativa da AWS ou do GCP, dependendo da sua infraestrutura existente, orçamento e requisitos de relatórios. 1. API → Cloud Run / Cloud Function → GCS Raw → BigQuery 2. API → Lambda → S3 Raw → BigQuery Data Transfer Service → BigQuery
Você consegue criar pipelines ETL incrementais?
Sim. Eu prefiro fortemente processamento incremental ao invés de reloads completos, por escalabilidade, menor custo no BigQuery e maior confiabilidade.
Você suporta transformações com dbt?
Sim. Posso criar modelos dbt para staging, limpeza, joins, lógica de negócio e tabelas de análise curadas.
Você consegue trabalhar com data warehouses ou pipelines existentes?
Sim. Posso melhorar, otimizar, depurar ou estender ambientes existentes no BigQuery, AWS ou ETL.
Você consegue integrar Power BI ou outras ferramentas de BI?
Sim. Posso preparar datasets prontos para análise, otimizados para Power BI, Looker Studio, Tableau e análises SQL.
Você oferece monitoramento e tratamento de erros?
Sim. Pipelines de produção incluem logging, retries, alertas e monitoramento para melhorar confiabilidade e estabilidade operacional.
Você consegue lidar com backfills históricos e grandes datasets de API?
Sim. Posso construir pipelines para sincronização histórica, APIs paginadas e datasets de grande escala com estratégias de carregamento otimizadas.