Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Ucrânia
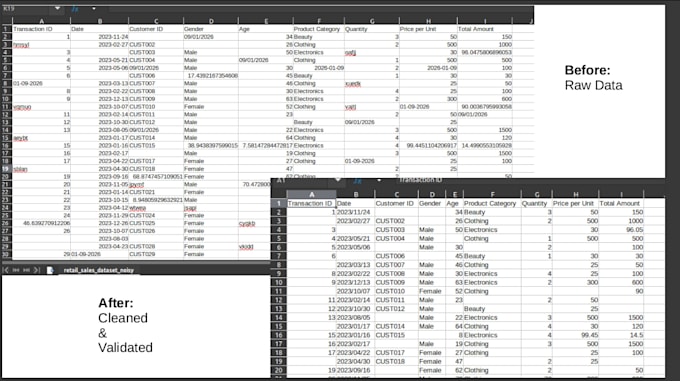
Databridge é um motor de processamento de dados local de alto desempenho, criado para transformar dados confusos e inconsistentes em um armazém SQL estruturado. Ele automatiza o processo de limpeza de dados, substituindo centenas de horas manuais por uma ferramenta única e segura.
Principais funcionalidades:
Automação em Python na sua melhor versão: Ideal para departamentos de e-commerce, finanças e marketing que lidam com relatórios fragmentados de fornecedores.


Tecnologia:
Python
•
Outros
Tradução automática
Como o motor lida com cabeçalhos não padrão?
Ele possui um normalizador robusto baseado em Regex. Qualquer cabeçalho como __&&UsER+nAME🥰 é automaticamente sanitizado para user_name. Usa correspondência fuzzy para encontrar as colunas corretas mesmo que seus nomes ou ordem variem entre os arquivos.
Quais são as regras específicas de transformação de dados?
Oferecemos uma biblioteca crescente de tipos: int, float, date, str, além de alpha (apenas letras) e identificador. Todos os tipos usam validação rigorosa e coerção de erro para lidar com dados "sujos" de forma segura. Mais tipos personalizados estão sendo constantemente adicionados ao motor.
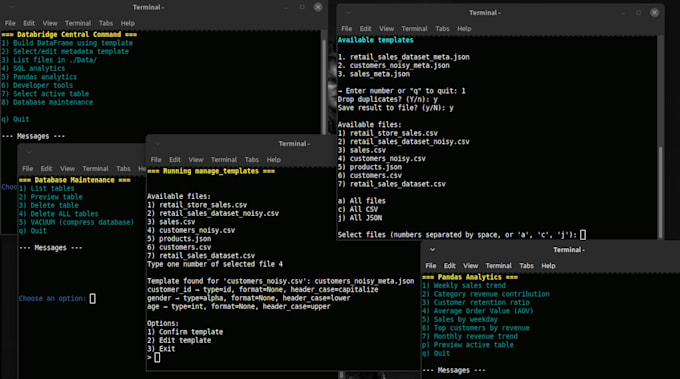
Como funcionam seus modelos JSON?
Os modelos atuam como um contrato. O motor usa regex para encontrar as colunas alvo independentemente de seus nomes ou ordem. Depois, converte estritamente os dados para os tipos e formatos escolhidos (int, float, date). Se uma linha estiver com dados ausentes ou falhar na validação conforme o modelo, ela é ignorada com segurança.
Posso processar muitos arquivos diferentes ao mesmo tempo?
Sim, no nível Enterprise, o "Modo Batch" permite apontar o motor para uma pasta. Ele percorrerá todos os arquivos, ignorando dados irrelevantes conforme seu modelo, e construirá uma base de dados consolidada linha por linha.
Como gerencio o banco de dados de saída?
A ferramenta inclui um Serviço de Banco de Dados. Você pode alternar entre tabelas ativas, excluir conjuntos de dados antigos e executar o comando VACUUM para desfragmentar o arquivo SQLite e liberar espaço em disco.
Quais são os requisitos do sistema?
Este é uma ferramenta CLI baseada em Python. Requer Python 3.9+ instalado na sua máquina. Todo processamento é local, ou seja, o desempenho depende do seu CPU/RAM, mas o motor é otimizado para operações em lote de alta velocidade.