Ver categorias
Explorar
Fiverr Pro
Português
$
USD
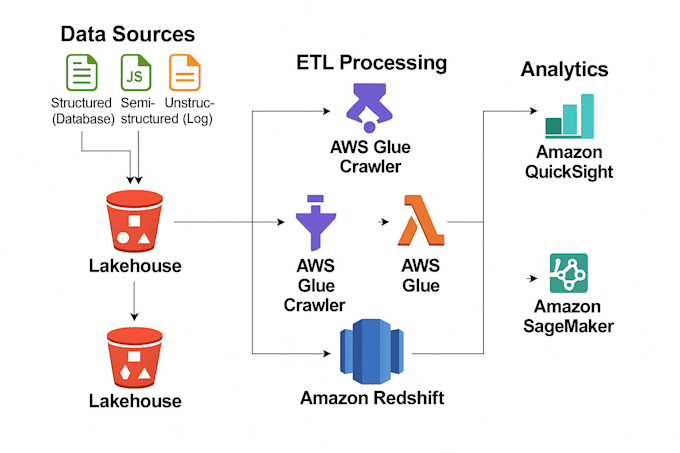
Eu projeto e construo pipelines de dados escaláveis, feitos sob medida para as necessidades do seu negócio. Usando Python, PySpark, SQL e AWS, automatizo a ingestão, transformação e armazenamento de dados para entregar informações limpas, confiáveis e prontas para análise. Realizo verificações de qualidade de dados, como detecção de valores ausentes, remoção de duplicatas, verificação de formato e validação de esquema para garantir a integridade dos dados.
Também crio dashboards interativos e relatórios com Amazon QuickSight e Tableau para ajudar você a monitorar KPIs e tomar decisões baseadas em dados com facilidade. Seja para workflows ETL, validação de dados, implantação na nuvem ou soluções de relatório, entrego sistemas otimizados e escaláveis.
Prioritizo comunicação clara, entrega pontual e suporte contínuo para ajudar sua infraestrutura de dados a evoluir junto com seu negócio. Vamos transformar seus dados brutos em insights acionáveis!
Especialidade:
Big data
•
Validação de dados
•
etl
•
Transformação
•
QA
•
SQL