Ver categorias
Explorar
Fiverr Pro
Português
$
USD




Tradução automática
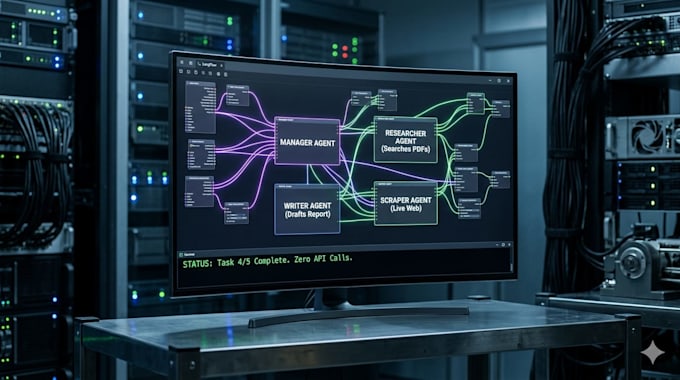
Eu construo Infraestrutura de IA Soberana sistemas privados, locais e de alto desempenho que rodam no seu hardware com Zero custos de API.
Como Arquiteto de Sistemas, especializo-me em implantar Grandes Modelos de Linguagem (LLMs) e agentes autônomos que priorizam Soberania de Dados e Privacidade. Seja você precisa de um assistente de pesquisa privado ou um fluxo de trabalho multi-agente complexo, entrego código limpo, pronto para produção e otimizado para execução local.
O que eu ofereço:
O entregável: Cada projeto inclui Código Fonte completo, um ambiente Dockerizado para configuração com um clique e documentação profissional. Você é o dono do sistema que eu construo.
Pare de pagar por tokens. Construa sua fortaleza.
Local Intelligence, Total Privacy, Expert AI Solutions
Idiomas
Tradução automática
Tradução automática
o que exatamente é "Sovereign Ai" e por que eu preciso dele?
Sovereign AI significa possuir sua inteligência ao invés de alugá-la. Eu construo sistemas que rodam no seu hardware ou nuvem privada. Nenhum dado sai da sua rede, e você paga zero de taxas mensais de API. É controle total sobre seus dados e seu futuro digital.
Preciso de um servidor de $10.000 para rodar LLMs locais?
Não. Usando quantização (GGUF/EXL2), otimizo modelos como Llama 3 para rodar em hardware de consumo. Uma RTX 3060/4060/5060 com 8GB VRAM é suficiente para um assistente privado de alta velocidade. Especializo-me em fazer modelos "pesados" rodarem em máquinas leves e eficientes.
A IA consegue ler meus documentos privados de forma segura?
Sim. Uso RAG (Retrieval-Augmented Generation) para criar um "Banco de Dados Vetorial" local. A IA busca seus PDFs, CSVs ou arquivos SQL em tempo real. Seus dados nunca tocam a internet e nunca são usados para treinar modelos públicos. Permanece 100% privado.
qual a diferença entre RAG e Fine-Tuning?
RAG é como um "exame de livro aberto" — a IA busca fatos nos seus dados. Fine-tuning é "cirurgia cerebral" — muda a personalidade ou jargão especializado da IA. RAG é melhor para precisão; Fine-tuning é melhor para uma voz única. Ofereço ambos para garantir total sinergia do sistema.
Isso é mais barato do que pagar pelo ChatGPT Plus ou APIs?
No longo prazo, com certeza. Embora haja um custo inicial, seu custo por mensagem fica $0,00. Para negócios de alto volume, uma configuração soberana geralmente se paga em 3-6 meses ao eliminar assinaturas recorrentes e dependência de fornecedores.
Como você entrega o produto final?
Forneço um "Sovereign Container" via Docker. Sem instalações complexas ou problemas com drivers. Você recebe um script de configuração com um clique e um README profissional. Execute o script e a IA é lançada no seu navegador como um aplicativo web privado e seguro.
você vai me ajudar na configuração inicial?
Todo pacote inclui um guia detalhado. Para os níveis Standard e Premium, ofereço uma sessão remota 1-a-1 para otimizar seu ambiente para sua GPU e VRAM específicas, garantindo o máximo desempenho de tokens por segundo possível.