Ver categorias
Explorar
Fiverr Pro
Português
$
USD




Tradução automática
Transforme seus documentos em um chatbot inteligente de IA que responde perguntas instantaneamente com fontes citadas e sem alucinações.
Sou engenheiro de backend com mais de 4 anos de experiência em produção construindo sistemas RAG para saúde e plataformas empresariais. Diferente de gigs genéricos de "wrapper do ChatGPT", entrego pipelines de produção reais: chunking adaptativo, recuperação híbrida semântica + BM25, reranking com cross-encoder e prompts conscientes de intenção que evitam respostas alucinatórias.
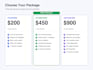
O QUE VOCÊ RECEBE:
TECNOLOGIAS:
Python, FastAPI, LangChain, ChromaDB, OpenAI, Claude, Gemini, LLMs de código aberto (Llama, Mistral), GCP, Docker.
FORMATOS SUPORTADOS:
PDF, DOCX, TXT, Markdown, HTML, CSV, páginas web, bancos de dados.
PERFEITO PARA:
Atendimento ao cliente, bases de conhecimento internas, perguntas e respostas de documentos legais, assistentes de políticas de RH, comércio eletrônico, fluxos de trabalho de saúde.
Python Backend Engineer
Idiomas
Tradução automática
Tradução automática
Quais provedores de IA / LLM você suporta?
Todos os principais provedores: OpenAI (GPT-4, GPT-4o), Anthropic Claude, Google Gemini e LLMs de código aberto como Llama 3, Mistral e Mixtral. Vou recomendar o melhor para suas necessidades de precisão, custo e privacidade.
Quais formatos de documento o chatbot consegue lidar?
PDF, DOCX, TXT, Markdown, HTML, CSV e URLs diretas (sites, sitemaps). Para PDFs complexos com tabelas ou conteúdo escaneado, uso parsers especializados. Integrações com Notion, Confluence e bancos de dados disponíveis mediante solicitação.
Eu fico com o código após a entrega?
Sim — propriedade 100%. Você recebe o código fonte completo em Python como um repositório limpo com documentação, pronto para implantar na sua infraestrutura. Sem lock-in de fornecedor, sem taxas recorrentes para mim. Totalmente seu para estender ou passar adiante.
Como você evita que o chatbot alucine respostas?
Três proteções: prompts de grounding rigorosos com fallback "não sei" quando o contexto falta, reranking com cross-encoder para que apenas os trechos mais relevantes cheguem ao LLM, e uma estratégia "Listar e Contar" para consultas de agregação que força a enumeração antes dos totais.
Você ajudará se houver problemas após a entrega?
Sim — cada pedido inclui 30 dias de suporte pós-entrega gratuito. Se for necessário ajustar a precisão da recuperação, farei iterações na estratégia de chunking, prompts ou parâmetros de reranking sem custo adicional. Grandes adições de escopo passam por extras do gig.
Devo enviar uma mensagem para você antes de fazer o pedido?
Sim, por favor! Envie detalhes sobre seus documentos (formatos, quantidade, sensibilidade), LLM preferido e exemplos de perguntas que seus usuários farão. Vou recomendar o nível adequado e confirmar o escopo antes de você fazer o pedido. Sem pressão, sem compromisso.


