Ver categorias
Explorar
Fiverr Pro
Português
$
USD
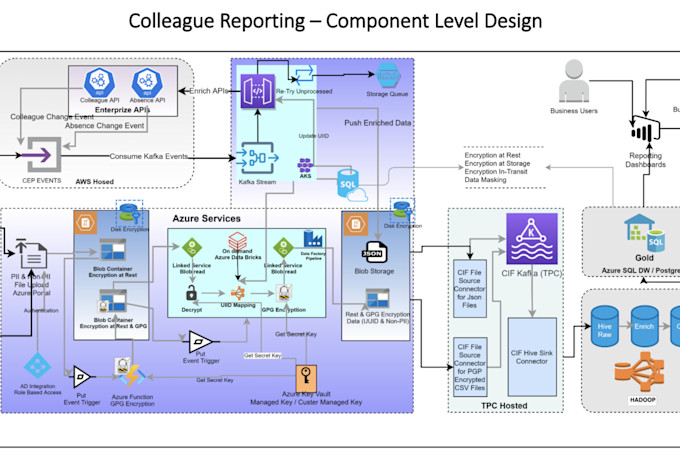
Engenheiro de Dados Sênior: AWS, Azure, Spark, pipelines ETL e arquitetura de dados
Tá tendo dificuldades com pipelines de dados lentos ou instáveis? Eu projeto e construo pipelines ETL de nível de produção na AWS e Azure que são rápidos, escaláveis e feitos para durar.
O que você vai receber:
- Design e implementação de pipelines ETL de ponta a ponta
- Otimização de performance do Apache Spark (PySpark, Scala)
- Configuração na AWS: Glue, Lambda, Step Functions, S3, Redshift
- Configuração no Azure: Databricks, Data Factory, Azure Data Lake Gen2
- Validação de dados, tratamento de erros e monitoramento
- Documentação completa e entrega
Ideal para:
- Empresas com pipelines de dados lentos ou que estão falhando
- Equipes migrando de on-premises para AWS ou Azure
- Projetos que precisam de otimização e tuning do Spark
- Desenvolvimento de ETL em tempo real ou em batch
Por que me escolher:
Mais de 5 anos construindo pipelines de dados empresariais nos setores de varejo, IoT e finanças. Já trabalhei com pipelines que processam milhões de registros por dia e vou aplicar essa mesma expertise no seu projeto.



Destination Platform:
Amazon Redshift
•
Amazon S3
Ferramentas e plataformas:
AWS Glue DataBrew