Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro de Dados Sênior, Spark, Scala, AWS, Airflow, Kafka, Big Data
Você está procurando um Engenheiro de Dados PySpark confiável para construir ou otimizar seus pipelines ETL?
Você está no lugar certo.
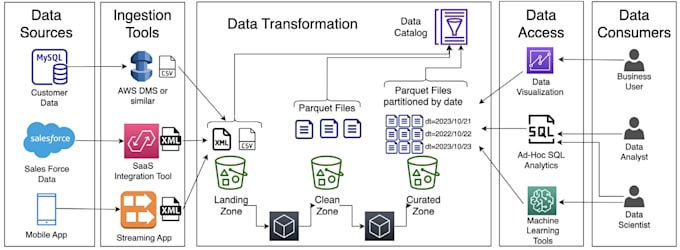
Sou Pankaj, um Engenheiro de Dados com mais de 3 anos de experiência na Paytm, onde criei mais de 200 pipelines ETL em produção processando mais de 5 TB/dia usando PySpark, Airflow, AWS e Kafka.
Este serviço foca 100% em entregar soluções PySpark ETL rápidas, escaláveis e limpas para o seu negócio.
O que posso fazer por você
Por que me escolher
Tecnologias que uso
Tem uma necessidade personalizada?
Me envie uma mensagem que respondo rapidinho.
Vamos construir algo escalável.

Tradução automática
O que você precisa de mim para começar?
Acesso a banco de dados/API, dados de exemplo, lógica SQL ou enunciado do problema.
Você pode se conectar ao meu banco de dados ou API?
Sim — MySQL, PostgreSQL, MongoDB, APIs, S3 e mais.
Você otimiza pipelines existentes?
Sim — Eu me especializo em otimização de runtime e depuração.
Você consegue integrar serviços AWS?
Sim — Glue, S3, EMR, Lambda, Athena.
Você pode assinar um NDA?
Sim — Posso trabalhar sob NDA, se necessário.