Execute modelos LLaMA localmente no seu próprio hardware e desbloqueie uma IA rápida e privada! Sou especialista em implantar LLaMA LLMs para iniciantes e desenvolvedores usando llama.cpp, um motor de inferência leve em C/C++ que permite inferência local de alto desempenho. Você terá uma configuração completa no Windows e Linux. sem nuvem, sem taxas recorrentes e controle total sobre seus modelos de IA.
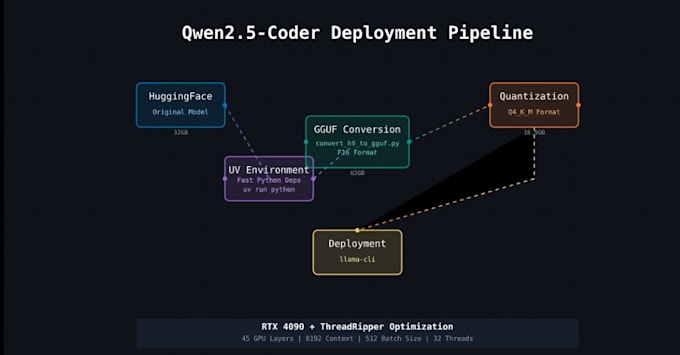
- Instalação Local: Vou instalar e configurar os modelos LLaMA (2/3) mais recentes ou compatíveis com GGUF na sua máquina. Seja no Windows, Linux ou Mac, cuido da configuração do ambiente, dependências e instalação do llama.cpp em modo de compilação ou binário.
- Otimização de GPU & CUDA: Com suporte à NVIDIA CUDA, vou ativar a aceleração de GPU (e multi-threading) para acelerar a inferência. Usando as otimizações do llama.cpp e quantização de modelos (4-bit/8-bit), vamos reduzir o uso de memória para que até modelos grandes funcionem suavemente (Modelos quantizados são muito mais leves e mantêm boa precisão).
- Ajuste fino & Dados personalizados: No pacote premium, faço o ajuste fino do seu modelo LLaMA com seu próprio conjunto de dados usando adaptadores LoRA (LoRA nos permite adaptar o modelo às suas necessidades treinando apenas os pesos do adaptador).