Ver categorias
Explorar
Fiverr Pro
Português
$
USD

Level 1
Data and Analytics Engineer
Habilidades
Conheça meus serviços
Quer trabalhar com remuneração por hora?
Diga a M. Abdullah o que você precisa.
US$ 25
/
horaFP&A Data - Analytics Engineer
Waseela • Período integral
Jun 2025 - Present • 1 yr 1 mo
1. Financial Data Modeling: Build and optimize data models to support budgeting, forecasting, and performance analysis across the Kisaan, Vets, and Milk business verticals. 2. Business Performance Insights: Develop dashboards and analytical reports that highlight financial KPIs, unit economics, cost structures, and revenue trends to strengthen decision-making. 3. Vertical Support & Analysis: Partner with FP&A, operations, and leadership teams to deliver data-driven insights for pricing, profitability, demand planning, and operational efficiency. 4. Data Integration & Automation: Streamline financial data ingestion from ERP, CMS, and field systems, ensuring accurate, timely, and automated data pipelines for monthly and quarterly reporting cycles. 5. Strategic Analytics: Support scenario modeling, variance analysis, and strategic planning by enabling reliable data visibility and analytics frameworks across all three verticals.
Data Extraction Engineer
Decision Inc. Australia • Período integral
Feb 2025 - Jul 2025 • 5 mos
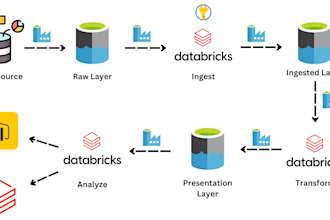
The role focused solely on Azure, incorporating Azure Data Factory, Databricks (PySpark transformations), and SQL Queries, along with a project in one of a wood window and door manufacturing company in the United States 1. Designed and implemented scalable ETL pipelines using Azure Data Factory, enabling seamless data extraction, transformation, and integration to support data-driven decision-making for a wood window and door manufacturing company in the United States. 2. Developed and optimized PySpark transformations in Azure Databricks, ensuring efficient data processing and transformation for large-scale datasets. 3. Automated data validation and integrity checks using Azure Data Factory and Azure Functions, ensuring a 99.7% validation rate while maintaining high data accuracy and compliance with business rules. 4. Collaborated with cross-functional teams to understand business requirements and deliver actionable insights, leveraging Azure Data Lake Storage (ADLS) for optimized data storage and processing. 5. Built cloud-based data architectures using Azure Synapse Analytics, Azure Data Lake, and Databricks, facilitating real-time and batch data processing to enhance business intelligence capabilities. 6. Optimized SQL queries for performance tuning in Azure SQL Database ensuring fast and efficient data retrieval for reporting and analysis. 7. Managed data integration and transformation workflows across Azure Data Lake and Databricks, enabling seamless data loading, transformation, and analysis for business stakeholders. 8. Developed end-to-end data pipelines for ingesting, transforming, and analyzing structured and unstructured data, leveraging Apache Spark and PySpark in Databricks for distributed computing and high-performance processing.
Associate Data Engineer
MetaSol • Período integral
Aug 2024 - Apr 2025 • 8 mos
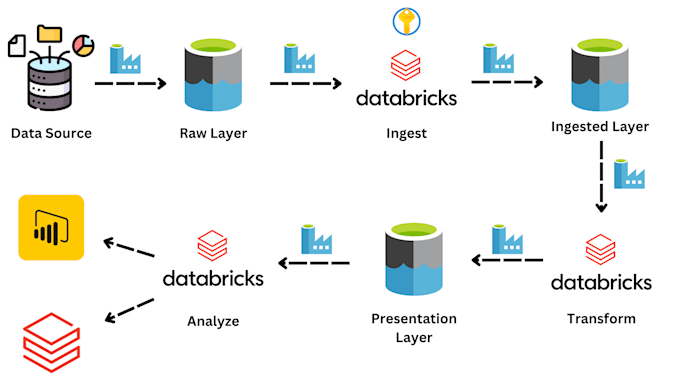
The role focused solely on helping the Senior Data Stewards by writing SQL, PySpark, and Bash scripts on AWS, incorporating PySpark transformations on AWS Glue and SQL queries on Athena, as part of a project for Europe’s largest telecommunications company. 1. Designed and implemented scalable ETL pipelines using AWS Glue, enabling seamless data integration and transformation across cloud platforms to support data-driven decision-making. 2. Automated data validation and integrity checks through AWS Lambda and Azure Logic Apps, ensuring high data accuracy (99.7% validation rate) while improving overall data quality and compliance with business rules. 3. Collaborated with cross-functional teams to understand business requirements and deliver actionable insights, leveraging AWS S3, Redshift, and Azure Data Lake. 4. Built data architectures using AWS and Azure services such as EC2, Glue, Lambda, and Azure Synapse Analytics, facilitating real-time and batch data processing for enhanced business intelligence capabilities. 6. Developed and maintained cloud-based data pipelines for large-scale data transformation, utilizing AWS S3 for storage, Glue for processing, and Redshift for analytics, ensuring data availability and scalability for business applications. 7. Managed data integration using AWS Redshift, Snowflake, and Azure SQL Data Warehouse, enabling seamless data loading, transformation, and analysis for business stakeholders. 8. Led data governance initiatives to ensure data security and integrity across platforms, utilizing AWS IAM, Azure Active Directory, and best practices in cloud security. 9. Developed end-to-end data workflows for ingesting, transforming, and analyzing structured and unstructured data, leveraging Databricks and PySpark for distributed computing and high-performance data processing. 10. Implemented lakehouse architecture using AWS Lake Formation, Azure Data Lake Storage, enabling scalable management and real-time analytics.
| (17) | ||
| (1) | ||
| (1) | ||
| (0) | ||
| (0) |
yz2017

Estados Unidos

jeanseo

Índia
tarsia
Cliente recorrente

Brasil

tarsia
Cliente recorrente
Brasil

alhassanali932

Emirados Árabes Unidos