Ver categorias
Explorar
Fiverr Pro
Português
$
USD


Tradução automática
Pare de gastar dinheiro com chamadas de IA redundantes!
A maioria dos aplicativos de IA desperdiça 40% a 80% do orçamento em chamadas redundantes de LLM. Estou aqui para ajudar você a parar essa perda.
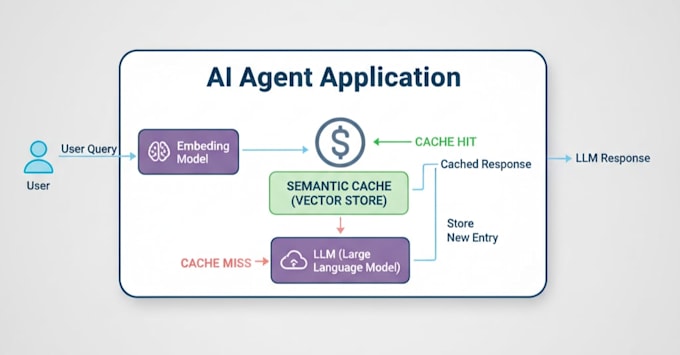
Vou criar um Cache Semântico Pronto para Produção que "lembra" consultas anteriores e fornece respostas instantaneamente, reduzindo seus custos e deixando seu app mais rápido que um raio.
O que é Cache Semântico?
O cache padrão é "burro" — precisa de uma correspondência palavra por palavra. O cache semântico é inteligente. Usando Embeddings de Vetores, seu sistema entenderá intenção. Se o Usuário A perguntar "Como está o tempo?" e o Usuário B perguntar "Qual a previsão?", o sistema sabe que são a mesma coisa. Ele fornece a resposta armazenada instantaneamente, sem precisar chamar sua API.
️ O que está incluído neste serviço?
Code, Scrape, Automate, FullStack Developer for Data and AI
Idiomas
Tradução automática
Tradução automática
O cache não fará a IA fornecer informações "antigas" ou "erradas"?
Não se for feito corretamente. Implementamos "Invalidação de Cache" e configurações de "Tempo de Vida" (TTL). Se seus dados mudam frequentemente, podemos configurar o cache para expirar a cada hora. Se os dados forem estáticos, podem durar para sempre. Também ajustamos o "Limiar de Similaridade" para que apenas perguntas realmente semelhantes ativem o cache.
Quanto de dinheiro realmente vou economizar?
Depende da sua "Taxa de Acerto do Cache". Para bots de suporte ao cliente ou FAQs, os usuários costumam fazer perguntas semelhantes, resultando em economias de 60-90%. Para bots de tarefas altamente criativas ou únicas, as economias geralmente ficam entre 20-30%.
Meus dados estão seguros?
Completamente. O cache fica hospedado na sua infraestrutura (ou na sua nuvem preferida). Eu não armazeno seus dados em meus próprios servidores.
Isso funciona com qualquer LLM?
Sim. Seja usando GPT-4 da OpenAI, Google Gemini 1.5, Claude 3.5, ou modelos locais como Llama 3, a camada de cache fica na frente da API, tornando-se independente do provedor.