Ver categorias
Explorar
Fiverr Pro
Português
$
USD





Tradução automática
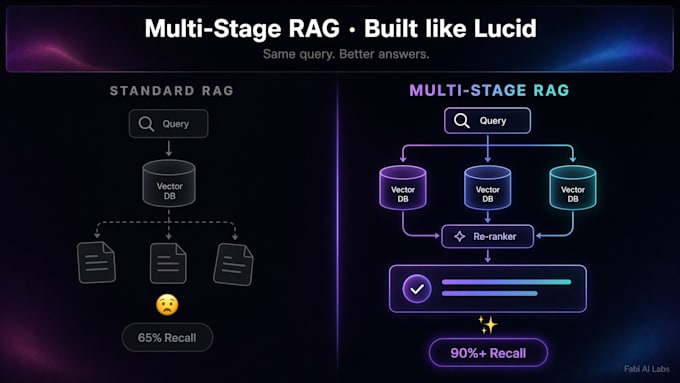
O RAG padrão encontra dificuldades com perguntas compostas. Um bot que responde a uma única consulta busca trechos que mencionam "reembolso" e perde nuances — regras de preço, cláusulas de dano, políticas de pedidos personalizados.
O RAG multi-stage é diferente. Ele se decompõe em sub-consultas, busca em paralelo, reclassifica e sintetiza. A taxa de recall sobe de 65% para mais de 90%. As respostas permanecem fundamentadas. As alucinações diminuem.
O QUE VOCÊ RECEBE:
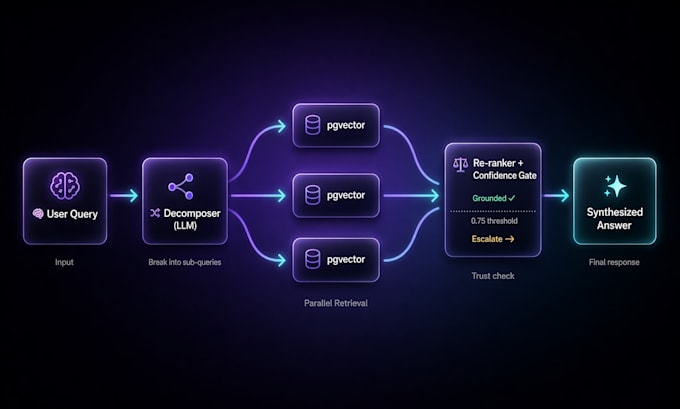
- Decomposição de consultas (LLM divide perguntas compostas em buscas específicas)
- Embedding de documento hipotético HyDE para recuperação
- Reclassificação + pontuação de confiança antes da geração da resposta
- 4 salvaguardas: transferência para humano, porta de incerteza, sem gaslighting, transparência
- Conjunto de avaliação personalizado com qualidade de recuperação mensurável
- Painel de administração para depuração de conversas + recuperação (Premium)
STACK: Python/TypeScript, Supabase pgvector, APIs OpenAI/Anthropic/Gemini, re-ranker personalizado.
POR QUE MULTI-STAGE: RAG de consulta única funciona para FAQs simples. Se seu bot lida com nuances de preço ou perguntas compostas, você precisa disso.
Isso é o que implementei no Lucid. Mesma arquitetura para seu domínio, ajustada ao seu estilo.
Envie seu caso de uso mais 10 perguntas difíceis que seu bot atual não consegue responder. Responderei com o escopo.
AI Developer and Creator of Lucid
Idiomas
Tradução automática
Tradução automática
Como o RAG multi-stage é diferente do RAG básico?
O RAG básico faz uma busca de vetor por pergunta. Para perguntas compostas, o recall de uma única busca é cerca de 65%. O RAG multi-stage decompõe a pergunta, busca em paralelo, reclassifica. O recall sobe para mais de 90%. Menos alucinações, respostas mais fundamentadas.
Isso vai custar mais do que o RAG básico em escala?
Frequentemente, menos. A decomposição usa modelos baratos (Gemini Flash por cerca de $0,10 por 1 milhão de tokens). A resposta final usa uma chamada de modelo premium. O RAG básico paga pelo premium em cada chamada. Com mais de 10 mil conversas por mês, o multi-stage costuma ser de 30 a 50% mais barato.
E se meus documentos forem bagunçados ou não estruturados?
Tratado como parte do escopo. Normalizo os documentos durante a ingestão — segmentando por limites semânticos (não por divisões de parágrafo ingênuas), limpando boilerplate, adicionando metadados para recuperação por filtro. Entrada bagunçada é a suposição padrão, não uma exceção.
Ainda preciso usar minhas próprias chaves de API?
Sim — mesma política do meu serviço Starter Bot. Você possui as contas OpenAI / Anthropic / Gemini, paga o preço direto sem markup, mantém controle total. Eu ajudo a escolher a combinação de modelos mais econômica para seu volume de tráfego.