Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro de software
Engenharia de Big Data Profissional para infraestrutura escalável e pronta para produção
Eu entrego soluções práticas de big data de ponta a ponta, desde o planejamento da arquitetura até a implantação e otimização, usando ferramentas padrão do setor. Cada solução é personalizada de acordo com seus objetivos, infraestrutura e requisitos de workload para garantir desempenho, escalabilidade e estabilidade a longo prazo.
Serviços incluídos:
Por que os clientes escolhem este serviço:


Idioma:
Inglês
•
Urdu
Experiência técnica:
Apache NiFi
•
apache spark
•
hadoop
•
Outros
Setor:
Data analytics
Tradução automática
Que tipos de projetos de big data você realiza?
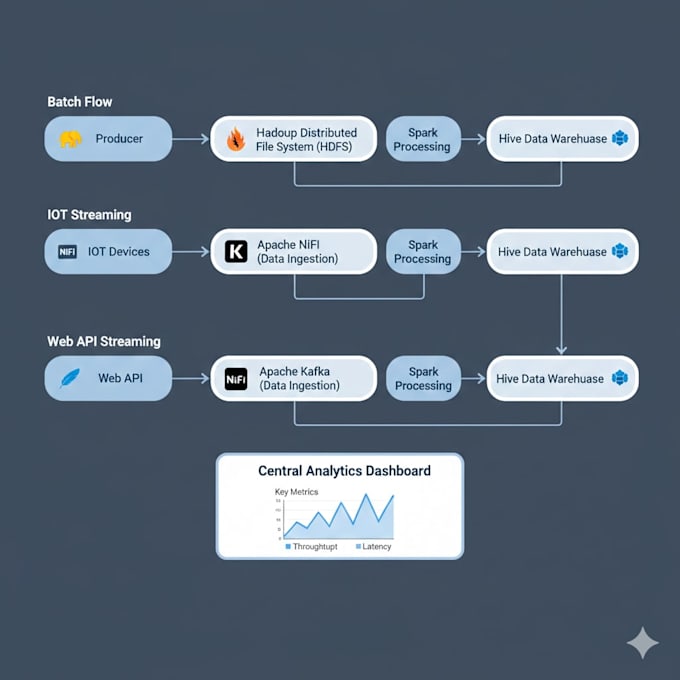
Eu cuido da configuração, implantação, otimização e resolução de problemas de ambientes de big data usando Hadoop, Spark, Kafka, Hive, NiFi e ferramentas relacionadas — desde sistemas pequenos de prova de conceito até clusters de produção.
Você consegue montar um cluster completo de Hadoop ou Spark do zero?
Sim. Posso projetar e implantar clusters totalmente funcionais, incluindo configuração, ajuste de desempenho e validação para garantir estabilidade.
Você oferece suporte a pipelines de streaming de dados em tempo real?
Com certeza. Eu crio pipelines de streaming baseados em Kafka e os integro com Spark ou NiFi para um processamento eficiente de dados em tempo real.
Você fornece documentação?
Sim. A documentação clara está incluída para te ajudar a entender, gerenciar e manter seu sistema.
como nós começamos?
Basta compartilhar seus requisitos, detalhes da infraestrutura e objetivos — eu vou propor o melhor plano de implementação.