Ver categorias
Explorar
Fiverr Pro
Português
$
USD



Tradução automática
Eu anoto suas imagens e treino um modelo YOLO personalizado que detecta SEUS objetos, não demos pré-treinados genéricos.
Sou membro do NVIDIA Inception com uma equipe de IA/ML em Python que já implantou sistemas de detecção de objetos na manufatura, segurança, restaurantes e análises esportivas em 6 países.
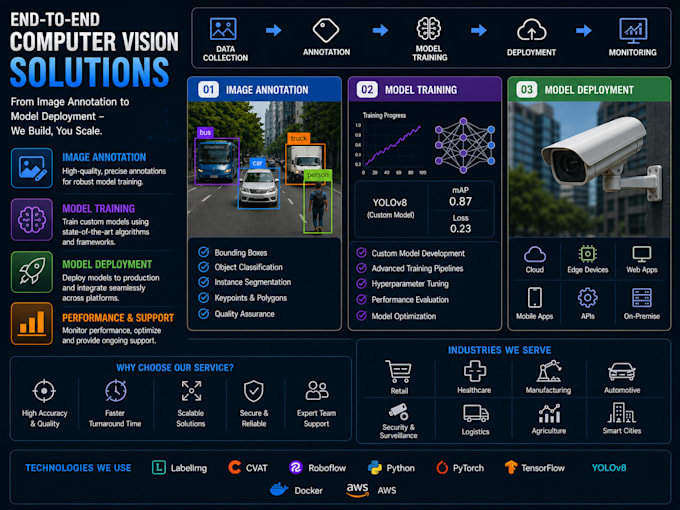
O QUE EU ENTREGUEI:
ETAPA 1 ANOTAÇÃO & ROTULAGEM
Anotação de caixa delimitadora, polígono ou ponto-chave
Ferramentas: CVAT, LabelImg, Roboflow, Label Studio, exportação no formato YOLO (yaml + labels txt)
ETAPA 2 PREPARAÇÃO DO CONJUNTO DE DADOS
Augmentação, divisão treino/validação/teste, auditoria de qualidade
ETAPA 3 TREINAMENTO DO MODELO YOLO
Treinamento personalizado do YOLOv8 no seu conjunto de dados, acelerado por GPU no NVIDIA CUDA, relatório de mAP, precisão, recall e matriz de confusão
ETAPA 4 IMPLEMENTAÇÃO (Apenas Premium)
Otimização com TensorRT, inferência 3-5x mais rápida, endpoint de inferência FastAPI, script Python pronto para rodar
O QUE EU CONSTRUI
Rastreamento de jogadores de futebol com 22 jogadores ao mesmo tempo
Detecção de fumar e EPI em hardware de borda NVIDIA Jetson
Monitoramento de conformidade de higiene na cozinha de restaurante
Você recebe: conjunto de dados rotulado, pesos do modelo treinado, script de inferência e relatório de treinamento.
Me envie uma mensagem antes de fazer o pedido com suas imagens e caso de uso.
AI App Development Expert, Computer Vision, OpenCV, Object Detection
Idiomas
Tradução automática
Tradução automática
Quais formatos de imagem você aceita?
JPG, PNG, BMP, TIFF e quadros de vídeo de MP4. Posso extrair quadros do seu vídeo, se necessário.
E se eu ainda não tiver dados rotulados?
Sem problema. A anotação é a primeira etapa. Envie as imagens brutas e descreva qual objeto você quer detectar.
Quantas imagens preciso para uma boa precisão?
No mínimo 200 por classe para detecção básica. Mais de 500 por classe dá entre 85% e 92% de mAP. Mais de 1.000 chega a 90% a 96%.
Você pode trabalhar com imagens médicas ou de satélite?
Sim. Envie uma imagem de exemplo primeiro e eu confirmarei a viabilidade antes de você fazer o pedido.
Você pode implantar no meu servidor em vez do Jetson?
Sim. Eu implanto via FastAPI na AWS, Google Cloud ou qualquer servidor Linux com suporte a GPU.