Ver categorias
Explorar
Fiverr Pro
Português
$
USD

Tradução automática
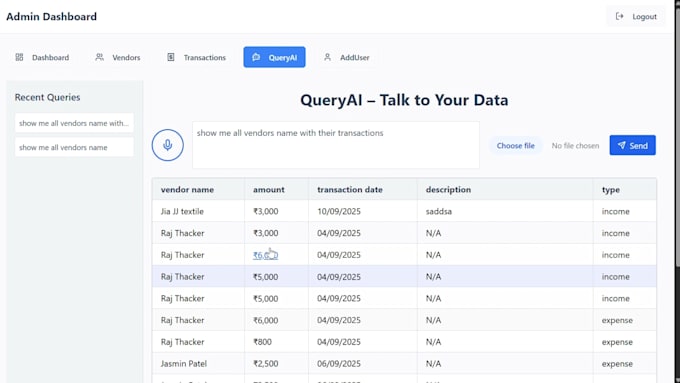
Precisa automatizar a extração de informações de documentos ao invés de fazer trabalho manual de copiar e colar? Eu crio soluções de automação baseadas em Python que processam arquivos de forma rápida, precisa e em grande escala.
Tenho experiência na criação de fluxos de trabalho para processamento de documentos para relatórios financeiros, gerenciamento de faturas, automação de planilhas de trabalho e pipelines de dados estruturados.
O que posso ajudar:
Extrair dados de faturas, recibos, formulários e documentos financeiros
Processar tabelas e informações estruturadas de arquivos complexos
Manipular documentos de várias páginas e arquivos escaneados usando OCR
Converter as informações extraídas em formatos JSON, CSV, Excel ou prontos para banco de dados
Construir scripts de automação ou fluxos de trabalho baseados em API para integração com sistemas existentes
Pilha de tecnologia: Python · pdfplumber · PyMuPDF · OCR · FastAPI · SQL
Os entregáveis incluem código limpo, instruções de configuração, documentação e exemplos de saída para testes.
Por favor, envie uma mensagem com um arquivo de exemplo e o formato de saída esperado antes de fazer o pedido, assim posso confirmar o escopo e a viabilidade.
Python Backend Developer with FastAPI REST APIs and AI Integration
Idiomas
Tradução automática
Tradução automática
Você consegue lidar com PDFs escaneados?
Sim, eu uso OCR (Tesseract/AWS Textract) para documentos escaneados.
Em qual formato será a saída?
JSON, CSV ou diretamente no seu banco de dados — você escolhe.
Você consegue processar PDFs automaticamente em uma agenda?
Sim, eu posso criar um pipeline automatizado no pacote Padrão ou Premium.