Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Sobre Este Gig
Sou especialista em construir sistemas multimodais de reconhecimento de fala e emoção combinando modalidades de áudio e texto para melhorar desempenho e precisão.
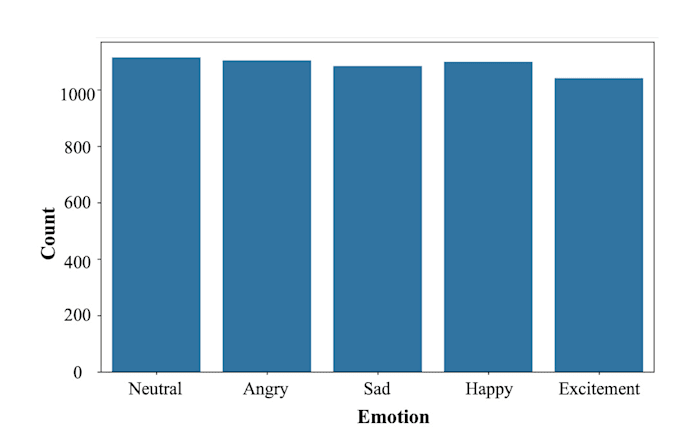
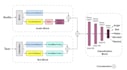
Com experiência prática em trabalhar com conjuntos de dados complexos como IEMOCAP e MELD, desenvolvi modelos híbridos personalizados usando Bi-LSTM e CNN, alcançando até 85% de precisão no conjunto de dados IEMOCAP. Também estou explorando ativamente Word2Vec e arquiteturas baseadas em Transformers para uma compreensão contextual aprimorada na fala.
Você pode conferir meus projetos e artigos de pesquisa linkados abaixo para mais detalhes.
O que eu ofereço:
Sinta-se à vontade para me enviar uma mensagem antes de fazer seu pedido para discutir suas necessidades específicas.

Especialidade:
Classificação
•
Fala e áudio
•
Análise preditiva
Linguagem de programação:
Python
•
Colab
APIs:
Outros
Ferramentas:
caderno Jupyter
•
Amazon SageMaker
•
Colab
Frameworks:
Scikit-learn
•
keras
•
PyTorch
•
Panda
•
fluxo tensor