Ver categorias
Explorar
Fiverr Pro
Português
$
USD
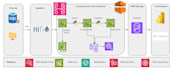
Engenharia de dados, Azure, AWS, Databricks, Lakehouse, Spark, Fabric
Seu silo de dados na AWS está isolado, não otimizado ou aumentando seus custos?
Como um Engenheiro de Dados Sênior com 9 anos de experiência, eu crio pipelines ETL na AWS de nível de produção que são automatizadas, econômicas e escaláveis. Sou especializado em transformar dados fragmentados do S3 em ativos estruturados e de alto desempenho para análises e IA.
O que eu resolvo para você:
Por que escolher este serviço?
Eu não apenas escrevo scripts; eu construo arquiteturas. Cada pipeline que entrego é projetado para ser serverless, minimizando sua conta mensal na AWS enquanto maximiza a taxa de transferência. Desde lógica de arquivamento no S3 até alertas automatizados, garanto que seus dados sejam governados e confiáveis.
Pronto para otimizar sua stack de dados na AWS? Vamos construir um pipeline escalável


Tradução automática
Quais serviços da AWS você usa para pipelines ETL?
Eu uso AWS Glue, S3, Redshift, IAM, CloudWatch e Spark, dependendo das necessidades do projeto.
Você consegue construir pipelines batch e incrementais?
Sim, eu projeto pipelines batch e incrementais com base no volume de dados e nos requisitos de latência.
Você faz validação de qualidade de dados?
Sim, implemento verificações de validação, aplicação de schemas e detecção de anomalias.
Você consegue otimizar pipelines existentes na AWS?
Com certeza. Otimizo desempenho, custo e confiabilidade.
Você fornece documentação?
Sim, documentação técnica completa e entrega.
Você suporta ingestão de dados via API?
Sim, APIs REST, bancos de dados e fontes de arquivos.
Você consegue construir pipelines CI/CD?
Sim, mediante solicitação.
A segurança é tratada?
Sim, roles IAM, criptografia e controles de acesso.
Você suporta pipelines em tempo real?
Sim, usando Kafka / Kinesis, se necessário.
Vocês oferecem suporte pós-entrega?
Sim, ofereço suporte após a entrega.


