Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Engenheiro de Dados, AWS, Apache Airflow, Spark, PostgreSQL, ETL
Você está afogado em dados brutos sem uma maneira confiável de processá-los?
Eu crio pipelines de dados de nível de produção que rodam automaticamente, escalam com seus dados e nunca falham silenciosamente. Sem scripts confusos. Sem etapas manuais. Apenas dados limpos e confiáveis exatamente onde você precisa.
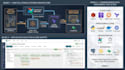
O que eu construo

Tradução automática
P: Quais informações você precisa para começar?
A: Sua fonte de dados (S3, API, banco de dados, CSV), seu destino, requisitos de transformação e a frequência com que o pipeline deve rodar.
Q: Você pode trabalhar com minha infraestrutura existente?
A: Sim. Envie-me os detalhes e avaliarei a compatibilidade antes de começarmos.
Q: Preciso de uma conta na AWS?
A: Para trabalhos baseados em AWS, sim — você precisará de sua própria conta. Posso te orientar na configuração, se necessário.
Q: Eu vou ser o proprietário do código?
A: Completamente. Todo o código fonte será entregue a você na entrega.
P: Vocês conseguem lidar com grandes conjuntos de dados?
A: Sim. Uso PySpark e EMR no EKS especificamente porque são feitos para processamento de dados em grande escala.
Q: E se algo quebrar após a entrega?
A: Ofereço suporte pós-entrega. Me envie uma mensagem e eu conserto.


