Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Bangladesh
Sobre mim
Você quer construir um modelo de aprendizado auto supervisionado (SSL) e descobrir clusters significativos nos seus dados?
- Você está no lugar certo! Sou um especialista em Deep Learning com experiência prática em SSL, clustering e avaliação de tarefas downstream.
Posso trabalhar com diversos conjuntos de dados de imagem, incluindo:
Por que escolher meu serviço?
O que entrego:
Vamos dar vida aos seus dados! Me envie uma mensagem antes de fazer o pedido para garantir que seus requisitos sejam totalmente compreendidos.



Especialidade:
processamento de imagem
•
Classificação
•
agrupamento
Linguagem de programação:
Python
•
Colab
•
Outros
Ferramentas:
caderno Jupyter
•
opencv
•
Colab
•
PyTorch
Frameworks:
PyTorch
•
Panda
•
Outros
Tradução automática
Que tipo de conjuntos de dados você pode trabalhar?
Posso trabalhar com qualquer tipo de conjunto de dados de imagens, incluindo imagens médicas, imagens de satélite, fotos de produtos ou conjuntos de dados pessoais/personalizados.
Preciso fornecer um conjunto de dados?
Sim. se você quiser que o modelo seja treinado com seus dados (produtos, rostos, documentos, etc.), você precisa fornecer as imagens. Se você não tiver um conjunto de dados, posso ajudar a coletar ou encontrar um por uma taxa adicional. Me envie uma mensagem primeiro!
Preciso de dados rotulados?
Não, o aprendizado auto supervisionado não requer dados rotulados. No entanto, labels podem ser necessárias se você quiser avaliação em uma tarefa downstream (pacotes Standard & Premium).
Existem limitações no tamanho do conjunto de dados?
Normalmente trabalho com conjuntos de dados que cabem na memória de GPU disponível, como Colab e GPU do Kaggle. Para conjuntos de dados muito grandes, podemos usar estratégias como amostragem, batching ou processamento distribuído.
Quais modelos de deep learning você usa?
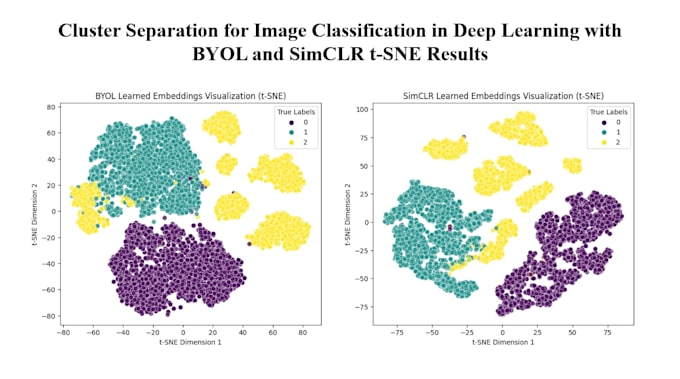
Uso modelos de aprendizado auto supervisionado de última geração, como SimCLR, BYOL, Barlow Twins.
Vou conseguir usar o modelo facilmente?
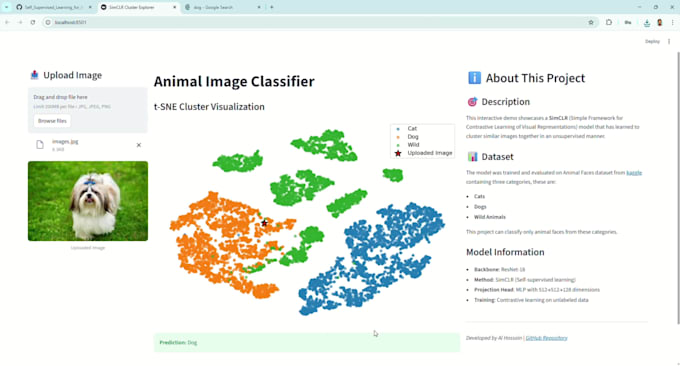
Sim! Para o pacote Premium, forneço uma aplicação web Streamlit amigável para explorar clusters e testar tarefas downstream de forma interativa.
Você consegue avaliar o desempenho do modelo?
Sim, forneço métricas detalhadas de avaliação em tarefas downstream, incluindo precisão, perda e visualizações dos clusters.
Vocês garantem a confidencialidade?
Sim, completamente. Seus dados e detalhes do projeto são mantidos estritamente confidenciais.