Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Índia
3 pedidos finalizados
Engenharia de Dados
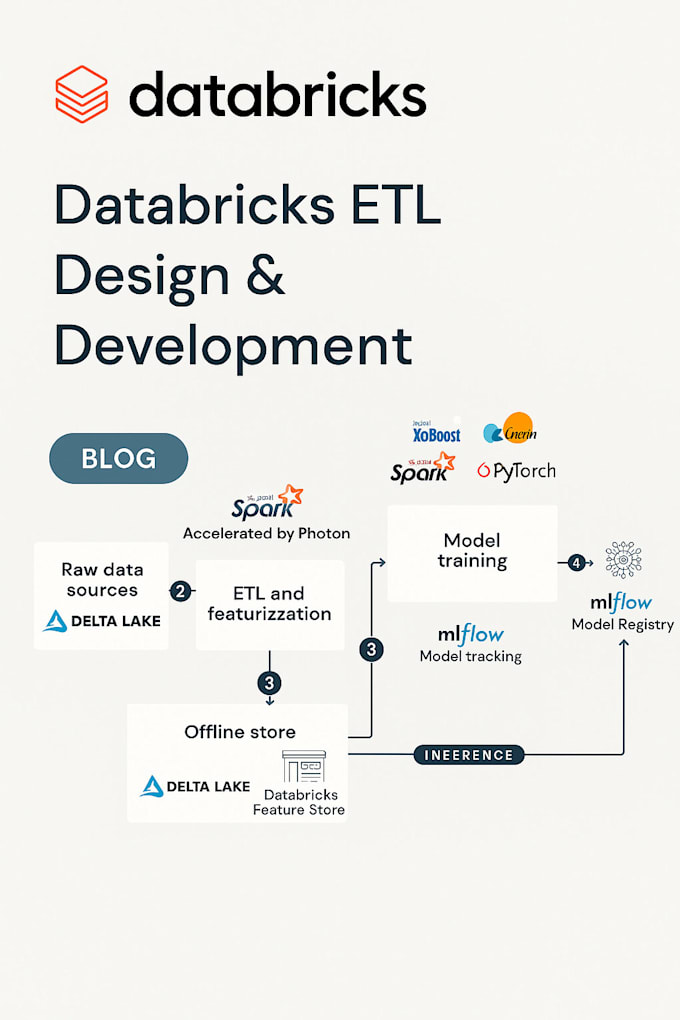
Precisa processar grandes conjuntos de dados de forma eficiente? Quer uma pipeline de dados robusta e escalável construída no Azure Databricks?
Como Engenheiro de Dados com mais de 3 anos de experiência, vou projetar, desenvolver e otimizar pipelines de dados de ponta a ponta usando Azure Databricks, PySpark e Delta Lake, totalmente integrados ao seu ecossistema de nuvem.
O que ofereço:



Tradução automática
O que você precisa de mim para começar
Por favor, compartilhe detalhes do sistema fonte, formato dos dados, lógica de negócio e destino final (por exemplo, Blob, SQL DB, ADLS)
Você irá implantar o pipeline no meu ambiente Azure?
Vou fornecer o código e instruções detalhadas de implantação. Implantação prática disponível como uma oferta personalizada
Você pode integrar isso com Azure Data Factory?
Sim! Posso orquestrar o job do Databricks via ADF, se necessário — mencione isso nos seus requisitos
Isso é adequado para cargas de trabalho de produção?
Com certeza — o pacote Premium inclui uma arquitetura de pipeline escalável, de nível de produção, com design modular de notebooks e modelagem de dados.