Ver categorias
Explorar
Fiverr Pro
Português
$
USD
Analista de dados, Engenheiro de dados na nuvem e especialista em Data Warehouse
Nível 1
Atendeu a determinados critérios de desempenho e demonstra forte potencial no marketplace.
Procurando uma solução confiável de pipeline de dados que mantenha as análises atualizadas e precisas?
Vou implementar pipelines modernos de engenharia de dados e data warehouses em Redshift, Google BigQuery, ClickHouse e Postgres.
ETL/ELT em lote e arquiteturas de streaming em tempo real, garantindo fluxos de dados confiáveis, automatizados e escaláveis para análises e modelos de IA/LLM.
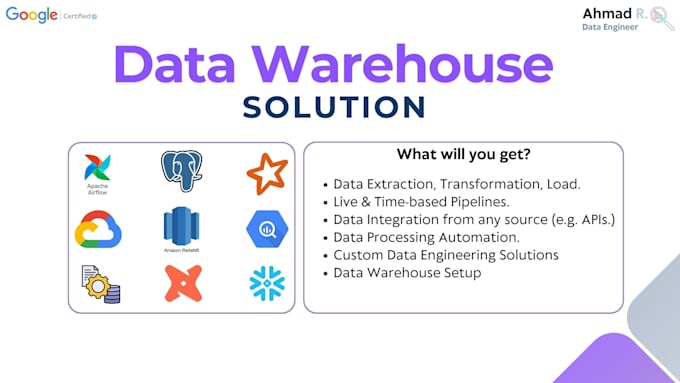
O que você recebe:
Minha stack:
Por que me escolher:
Engenheiro de Dados com mais de 7 anos de experiência. Especializado em Redshift, Bigquery, PostgreSQL e arquiteturas personalizadas de data warehouse.


Tradução automática
Qual a diferença entre pipelines ETL e ELT?
ETL extrai, transforma e depois carrega os dados; ELT carrega os dados brutos e depois transforma na warehouse (comum no BigQuery). Podemos implementar qualquer um de acordo com suas necessidades.
Qual data warehouse é melhor para mim?
Redshift funciona melhor para grandes cargas de trabalho de análises na AWS. BigQuery é um warehouse totalmente serverless do GCP para consultas rápidas e escaláveis. PostgreSQL é ótimo para dados moderados e consultas SQL complexas. ClickHouse se destaca em OLAP de alta velocidade e análises em tempo real. A escolha depende da escala dos seus dados e do caso de uso.
Você consegue lidar com dados de streaming?
Sim – construo pipelines em tempo real usando Kafka, Kinesis ou GCP Pub/Sub. Streaming ETL está incluso no pacote Premium para fluxos de dados atualizados.
O que você precisa de mim para começar?
Por favor, forneça detalhes das suas fontes de dados (tipo, acesso), data warehouse desejado, dados/schema de exemplo e objetivos do projeto (relatórios, uso de ML). Isso ajuda a personalizar a solução.
Como você usa IA no pipeline?
Uso ferramentas de IA para automatizar partes do fluxo de trabalho – por exemplo, usando GPT para criar códigos de transformação ou inferir esquema de dados, e aplicando modelos BigQuery ML/Redshift ML via SQL para recursos preditivos (quando relevante).