Ver categorias
Explorar
Fiverr Pro
Português
$
USD

Level 2

Tradução automática
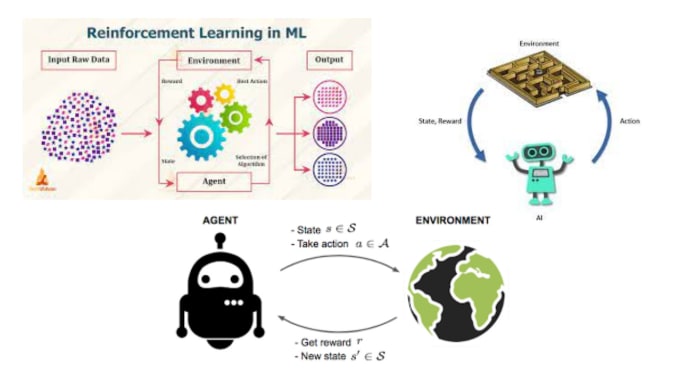
Agentes de Policy Gradient: Aproveite o poder dos métodos de Policy Gradient, permitindo que seus agentes de IA aprendam políticas ótimas através de ascensão de gradiente. Sou especializado em projetar, treinar e ajustar esses agentes para várias aplicações.
Deep Deterministic Policy Gradient (DDPG): Tire vantagem do DDPG, um algoritmo de ponta para espaços de ação contínuos. Posso ajudar você a implementar e otimizar agentes DDPG para tarefas como robótica, sistemas de controle e veículos autônomos.
Proximal Policy Optimization (PPO): PPO é conhecido por sua estabilidade e robustez em RL. Posso orientar você no uso do PPO para treinar agentes em ambientes complexos, garantindo rápida convergência e resultados de alto desempenho.
Arquiteturas Actor-Critic: Utilize métodos Actor-Critic para espaços de ação discretos e contínuos. Aproveite a sinergia da aproximação da função de valor e otimização de políticas para resolver problemas desafiadores de RL.
Integração de Redes Neurais: Aproveite o poder das redes neurais profundas para melhorar as capacidades de aprendizado dos seus agentes de RL, garantindo que eles se adaptem e se destaquem em ambientes complexos.
optimized AI Models
Level 2
Idiomas
Tradução automática
