Ver categorias
Explorar
Fiverr Pro
Português
$
USD

Lead Software Engineer
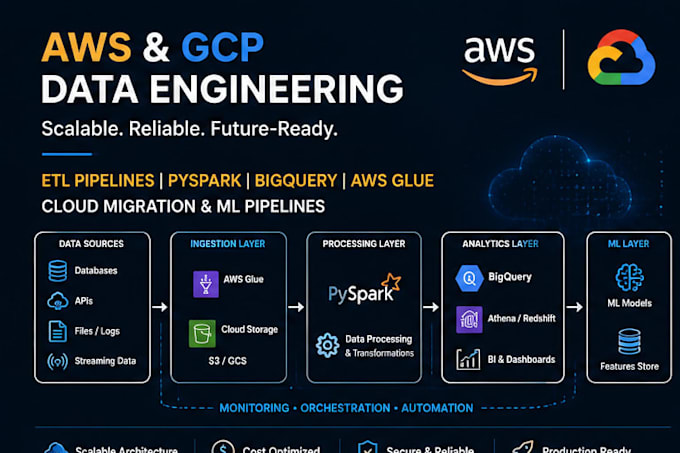
Habilidades
Conheça meus serviços
Senior Data Engineer
Ideal Designhouse • Período integral
Jul 2025 - Present • 11 mos
LLM Platform Ownership: Led the design and development of a production-grade LLM platform using OpenAI and Gemini to generate promotional titles from minimal product inputs (UPC), improving content creation efficiency by 90% through custom prompt engineering and evaluation workflows. Data Platform Architecture: Architected scalable and distributed PostgreSQL to Amazon S3 ETL pipelines using PySpark, AWS Glue, and EMR Serverless, processing over 100 GB daily while optimizing compute and storage costs by 40%. Multi-Cloud Strategy: Directed zero-downtime migration of large-scale datasets from AWS S3 to Google Cloud Storage using Storage Transfer Service, enabling unified multicloud analytics capabilities. Customer Analytics Enablement: Implemented Google Analytics 360 event tracking and collected data on promotional sites for standardized behavioral data, enhancing product and marketing insights. Leadership & Delivery: Designed hierarchical product performance dashboards (brand to sub-brand to store group to store) and mentored a team of engineers to deliver end-toend analytics solutions for enterprise clients.
Member Of Technical Staff
Andromeda Security • Período integral
Jan 2025 - Jun 2025 • 5 mos
Cloud Risk Evaluation with LLMs: Integrated service categorization and access-level analysis using large language models (LLMs) to evaluate the criticality of cloud resources and actions, improving accuracy (by 15 %) in risk assessment and access control. User Behavior Insights: Analyzed user login data to identify trends for feature optimization and enhanced user experience. Automated Data Migration: Engineered a robust pipeline for migrating transformed data from Kafka to Amazon S3, leveraging Kubernetes pods to ensure scalability and reliability. Real-Time Data Lake Monitoring: Planned and implemented Python-based metrics computation scripts integrated with Datadog, enabling proactive monitoring and real-time performance tracking of data lake infrastructure.
Senior Data Engineer
Quicken • Período integral
Nov 2021 - Jan 2025 • 3 yrs 2 mos
Automated Data-Orchestration Pipeline: Developed a centralized pipeline with AWS Step Functions, EMR Serverless, Lambda, SQS, EventBridge, and PySpark. Routinely purged PII from Apache Hudi tables on S3, enhancing compliance and data governance. Subscriber & Churn Analytics: Audited user activity and subscription data in Athena to identify subscribers, renewals, and churn, enabling data-driven engagement and retention strategies. Cost Prediction & Optimization: Built and presented a refined ML-based cost prediction model by analyzing historical AWS usage data, improving cost forecasting accuracy and enabling proactive optimization. Scalable Data Ingestion: Designed managed pipelines to batch-ingest data from multiple sources (Amazon Kinesis, BigQuery, Salesforce, DMS, AWS Redshift) into standardized Apache Hudi tables, streamlining transformation and storage. Data Quality & Monitoring Framework: Engineered a monitoring framework with custom validation checks to enforce data integrity, troubleshoot issues, and ensure quality across the data lake. Metadata Repository: Built AWS DynamoDB repository for real-time data lake metadata, enhancing discovery and governance. Automated Product Review System: Architected a workflow to identify eligible customers and trigger personalized email campaigns, driving user engagement and successfully converting free users into paying customers.
